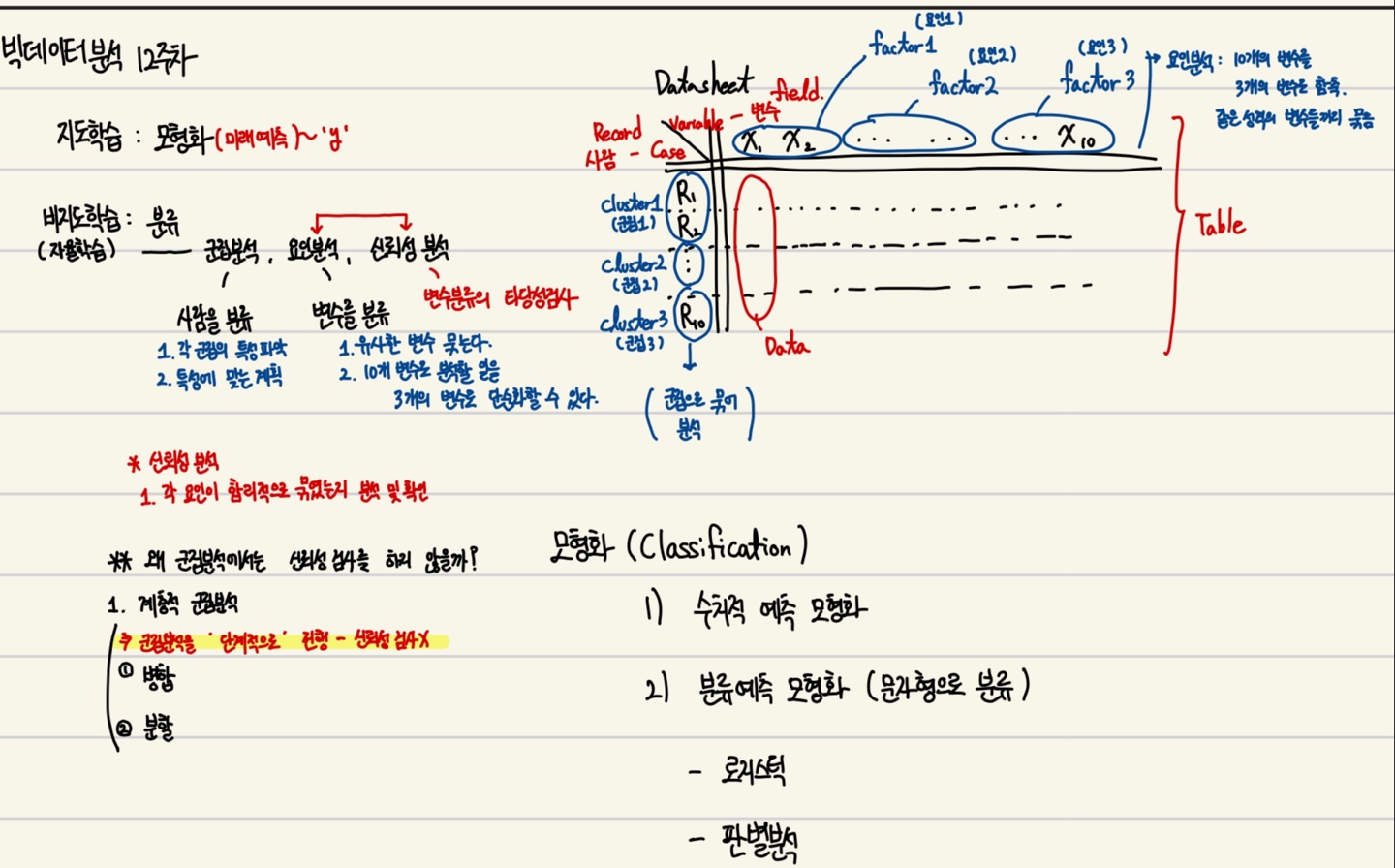
지도학습 VS 비지도 학습지도학습의 특징으로는 "미래를 예측한다" 이다. 여러 X 독립변수들을 가지고 하나의 종속 변수 Y를 예측하는 모형을 모형화시킨다.비지도학습의 큰 특징으로는 "분류" 이다. 비지도학습에는 군집 분석, 요인 분석, 신뢰성 분석이 있고 크게 보면 군집분석과 요인+신뢰성 분석이다. 군집분석은 사람들을 분류하여 각 군집의 특성을 파악하고, 특성에 맞는 계획을 수립한다. 요인분석은 변수(요인, Factor)들을 분류하여 유사한 변수들끼리 묶는다. 10개 변수로 분석할 일을 3개의 변수로 단순화할 수 있다. Q 왜 군집분석에는 신뢰성 검사를 하지 않을까? A 계층적 군집분석을 예시로, 군집분석은 단계적으로 진행이 되기 때문에, 신뢰성 검사가 따로 필요하지 않다. ★ 신뢰성 분석은 시험..