-기초통계-
추론 통계 (평균의 분포)



추론통계 : 샘플의 데이터를 기반으로 더 큰 모집단에 대해 예측하거나 결론을 도출할 수 있다.
→ 두 모집단의 평균, 분산(편차), 데이터 수가 다를 때 두 모집단의 평균이 차이가 있는지 판단하기 위해서
- 목적 : 추론 통계는 의미 있는 결론을 도출하고 샘플 데이터를 기반으로 모집단에 대한 예측을 수행하는 역할을 함
- 이러한 방법을 통해 모집단 매개변수에 대한 정보에 입각한 추측을 하고 가설을 테스트하며 결과의 신뢰성을 평가할 수 있음
- 측정 유형 : 추론 통계는 범주형 측정과 연속 측정 모두에 적용가능 데이터의 특성과 연구 질문에 적응하여 다양한 분야와 시나리오에 적용이 가능하다
- 표현 : 추론 통계는 수학 공식과 확률 모델을 활용하여 모집단 매개변수를 추정하거나 관찰된 결과의 가능성을 결정함
- test values, 신뢰 구간, p-값 이러한 표현을 통해 불확실성을 정량화하고 증거를 기반으로 결정을 내림
- → p-value 값 매우 중요!!!
- 사용 : 추론 통계는 사회 과학에서 자연 과학, 비즈니스 및 그 이상에 이르기까지 수많은 영역에서 사용됨
- 이러한 기술을 사용하여 가설을 검증하고, 그룹을 비교하고, 변수 간의 관계를 평가하고, 미래 추세를 예측
- 의사 결정, 정책 수립 및 데이터 내에 숨겨진 패턴 발견 및 추론 통계는 관찰된 샘플의 범위를 넘어서는 더 광범위한 의미 를 갖는 통찰력을 발견할 수 있는 수단을 제공
가설 검정 및 추론 통계
- 데이터의 구조를 뜯어봤고, 이 데이터를 실제로 사용할 필요가 있는지 없는지를 판단하기 위해 가설 검정
- 가설 설정은 유의한 효과, 관계 또는 차이가 있는지 여부를 결정하기 위한 가설 검정의 초기 단계
- 모델이나 테스트를 사용한 후속 통계 분석은 가설에 대한 증거를 평가하는 데 도움이 되며 관찰된 데이터를 기반으로 연구 중 인 모집단에 대한 구체적인 판단으로 이어짐
- 가설 검정에서는 표본(모집단의 하위 집합)을 가설 값이나 다른 표본과 비교하여 모집단에 대한 결론을 도출함
- 세상의 모든 데이터를 모집단으로 수집할 수 있으면 가설 검정을 진행할 필요가 없음

가설 검정에서 핵심은 귀무가설과 대립가설이다. 귀무가설은 보통 영향이 없다, 차이가 없다, 현상을 유지한다가 기본 BASE이고, 대립가설은 귀무가설과는 반대로 효과가 있다, 차이가 있다, 바라는 상황이 들어온다.

※ 유의수준은 0.10, 0.05, 0.01 중으로, 연구자가 설정하는 것이지만 유의수준보다 p-value가 작으면 귀무가설을 기각하고, 반대의 경우에는 귀무가설을 채택한다.
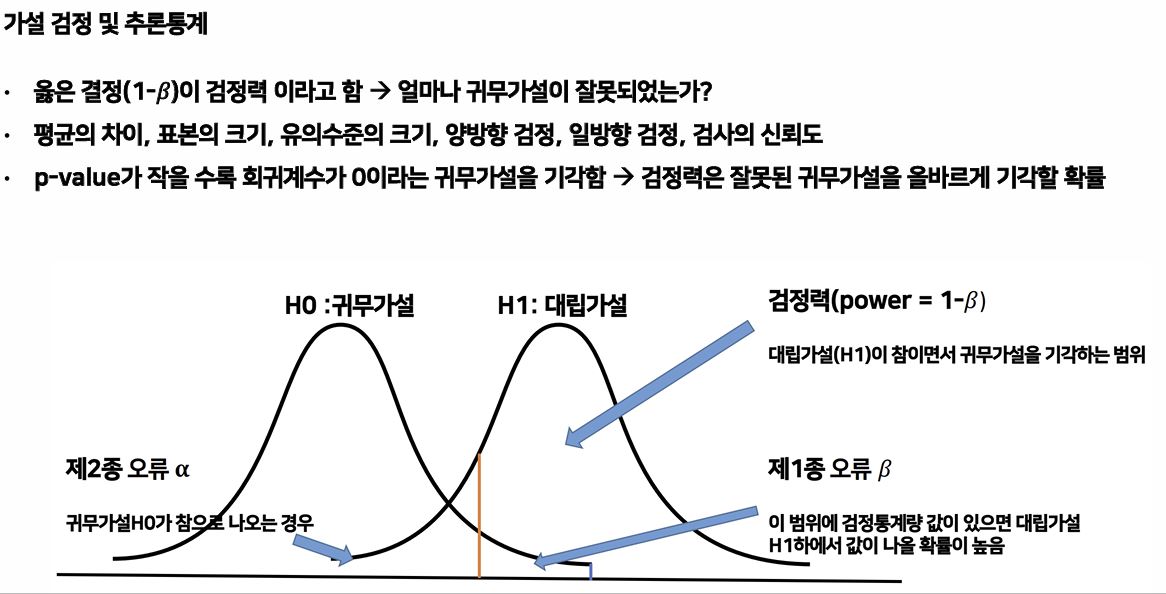






가설 검정 및 추론통계
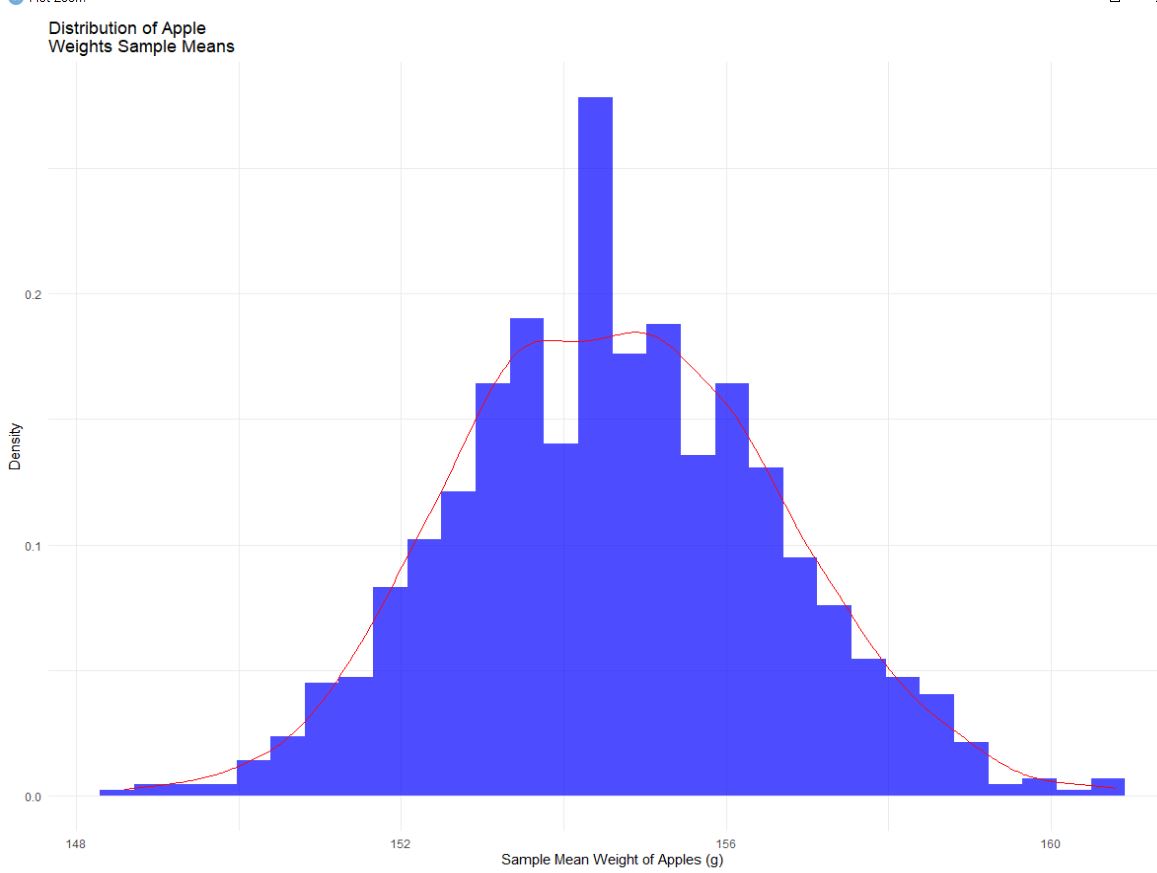
- Z-test : Z-test는 t-test와 유사하지만 표본 크기가 크고(일반적으로 n ≥30) 모집단 표준 편차를 알고 있을 때 사용됨
- 그룹의 평균이 가설 값과 유의하게 다른지 테스트함
- 과거의 경험, 많은 샘플수로 모집단을 예측할 수 있으므로 모집단의 표준편차를 알고 있다고 할 수 있음
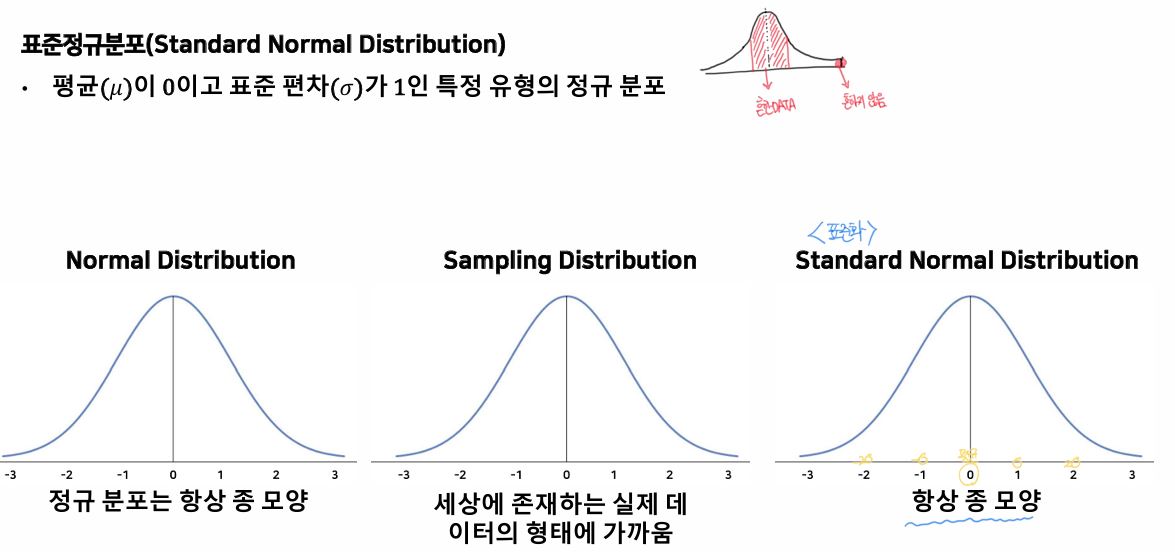
- 표준정규분포의 평균의 분포 ➔ 0을 기준으로 정규분포를 이룸

가설 검정 및 추론통계(차이 파악)
- T-TEST : t-test는 두 그룹의 평균을 비교하거나 모집단 표준 편차를 모를 때 단일 그룹의 평균의 차이를 테스트하는 데 사용 (데이터 수가 30개 이하로, 모집단의 표준편차를 알지 못할 때)
- T-TEST : t-test는 두 그룹의 평균을 비교하거나 단일 그룹의 평균이 가설 값과 유의하게 다른지 테스트하는 데 사용됨
- 데이터가 대략적으로 정규분포를 이루고 표본크기가 작은 경우에 적용할 수 있음 (n ≤ 30)
- 모집단을 대표하는 표본 으로부터 추정된 분산이나 표준편차를 가지고 검정하는 방법으로 두 모집단의 평균 간의 차이를 검정한다.
- 데이터가 대략적으로 정규분포를 이루고 표본크기가 작은 경우에 적용할 수 있음(n≤30) →평균의 분포
- Z-TEST : Z-test는 t-test와 유사하지만 표본 크기가 크고(일반적으로 n > 30) 모집단 표준 편차를 알고 있을 때 사용
- 그룹의 평균이 가설 값과 유의하게 다른지 테스트함 → 평균의 분포

t-test의 특징
- 관찰의 독립성 : 비교되는 두 그룹의 데이터는 서로 독립적이어야 함
- 정규성 : 비교되는 두 그룹 각각의 데이터는 대략 정규 분포를 따라야 함 & 무작위로 샘플링이 가능해야 함
- 이상값 없음 : 데이터에 극단값이나 이상값이 없어야 함
- 연속성 : 수치값을 가지거나 연속적이여야 함
- 이 비율이 1에 가까우면 등분산(예: 0.5와 2 사이)
- 자유도(df) : 매개변수를 추정하는 데 사용할 수 있는 독립적인 정보의 수를 반영함
- 표본분산 : 모집단에서 추출한 여러 가능한 표본에 대한 통계의 변동성 또는 분산





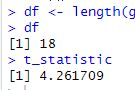




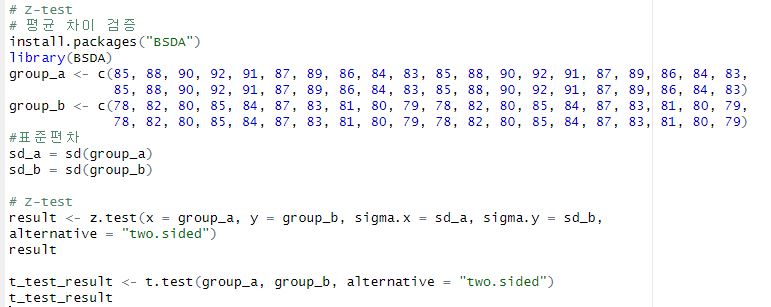

[가설 검정 및 추론통계]
▶ T-Test, Z-Test 결과값이 미미하게 다르게 나오지만, 같은 결과값이 나온다!!!
모집단 표준 편차의 가정
- Z-test : 모집단 표준 편차를 알고 있다고 가정
- T-test : 모집단 표준 편차를 알 수 없다고 가정
샘플 크기
- Z-test : 더 큰 샘플 크기(n ≥ 30)에서 잘 작동
- T-test : 더 작은 샘플 크기와 더 큰 샘플 크기에서 잘 작동
테스트 통계 분포
- Z-test : 테스트 통계는 표준 정규 분포(z-distribution)를 따름
- T-test : 테스트 통계는 자유도(샘플 크기 관련)에 따라 달라지는 t-분포를 따름
테스트 통계량 계산
- Z-test, T-test
- 표본 평균과 모집단 평균의 차이를 비교
- 표본의 변동성을 고려하여 표본 평균과 가설 평균의 차이(또는 쌍 표본 간의 차이)를 비교
가설 검정 및 추론통계 (시험출제!)
- 가설 설정
- 유의수준 선택
- 자유도 계산
- 검정 통계량 계산
- P-value값 계산
- 결론 도출
[기말고사 출제]



'머신러닝1 > 수업 필기' 카테고리의 다른 글
| 머신러닝1 필기 (12, Just 참고용) (0) | 2024.06.09 |
|---|---|
| 머신러닝1 필기 (10, 기말 대비 실습) (0) | 2024.06.09 |
| 머신러닝1 필기 (9) (1) | 2024.06.09 |
| 머신러닝1 필기 (8) (0) | 2024.06.08 |
| 머신러닝1 필기 (7) (0) | 2024.06.08 |