



1. 기존 데이터(확률표본)로 예측 확률 계산
→ 왜 계산 ? 서버의 참값과 비교하기 위하여 (모형의 타당성과 정확도)
2. 실제 데이터 (New Data)
→ P값을 구한다.
<검정>
- Z-분포 : 한 집단 검정할 때 쓰인다.
- T-분포 : 두 집단 검정할 때 쓰인다. → 계수(를 찾기 위해)
- F-분포 : 모형검정
- 카이제곱 분포 : 문자형들에 대한 적합도를 구하기 위해
- ANOVA : 세 집단 이상의 비교를 할 때, 분산분석 (아노바) 을 한다.

[ 중간고사 출제 가능성 Top ]
1. 빅데이터분석의 정의 및 개요 (4V, 정형데이터, 비정형데이터 엮어서)
2. 하둡의 정의와 구성요소
3. 맵리듀스 과정 풀어쓰시오.
4. 그림 표주고 유의한지 안한지 해석하시고 표에서 알 수 있는 것들 적으시오.
5. 오즈비
6. 검정 4가지 단계 : 1) 가설설정 2) 검정통계량 3) 기각역 설정 4) 결론
7. 적합도, 오분류율을 찾아 쓰시오.
8. 로지스틱회귀식에서의 계수가 갖고있는 의미
9. 빅데이터 처리기술
10. 클라우드 컴퓨팅의 정의 및 확산 원인 (분산 시스템이랑 엮어서)
11. 검정의 쓰임 (Z-분포, F-분포, 카이제곱 분포, T-분포, ...)
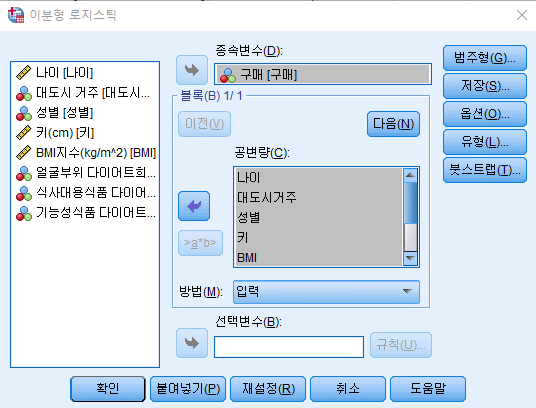
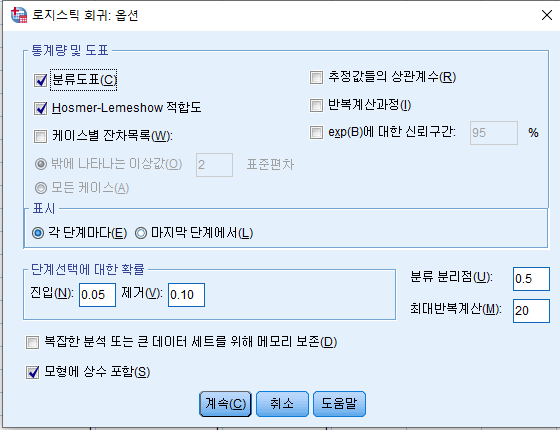
[ 실습, SPSS ]





'빅데이터 분석 > 수업 필기' 카테고리의 다른 글
| 빅데이터분석 필기 (9) (1) | 2024.06.09 |
|---|---|
| 빅데이터분석 필기 (8) (0) | 2024.04.21 |
| 빅데이터분석 필기 (6) (0) | 2024.04.21 |
| 빅데이터분석 필기 (5) (0) | 2024.04.21 |
| 빅데이터분석 필기 (4) (0) | 2024.04.21 |