[ 복습 ]
산점도
- 두 변수의 관계를 알 수 있다.
- 상관관계를 알고 상관분석을 할 수 있다.
- 관계를 숫자로 나타낸 것이 상관계수이다. (상관계수 : r)
빅데이터 분석 : 표본의 상관계수로 전체를 분석 및 미래를 예측하는 것
회귀분석 : 참값에 유사한 근삿값을 갖는 직선 (회귀직선) 을 그리도록 모형화하는 것
상관관계
- 두 변수 간 인과관계를 알려주지는 않는다.
인과관계
- 두 변수 간의 상관이 존재한다.
- 원인이 되는 변수가 결과가 되는 변수에 시간적으로 선행한다.
- 원인 변수 외에 영향을 미치는 제 3의 변수가 제거되어야 한다.
회귀분석
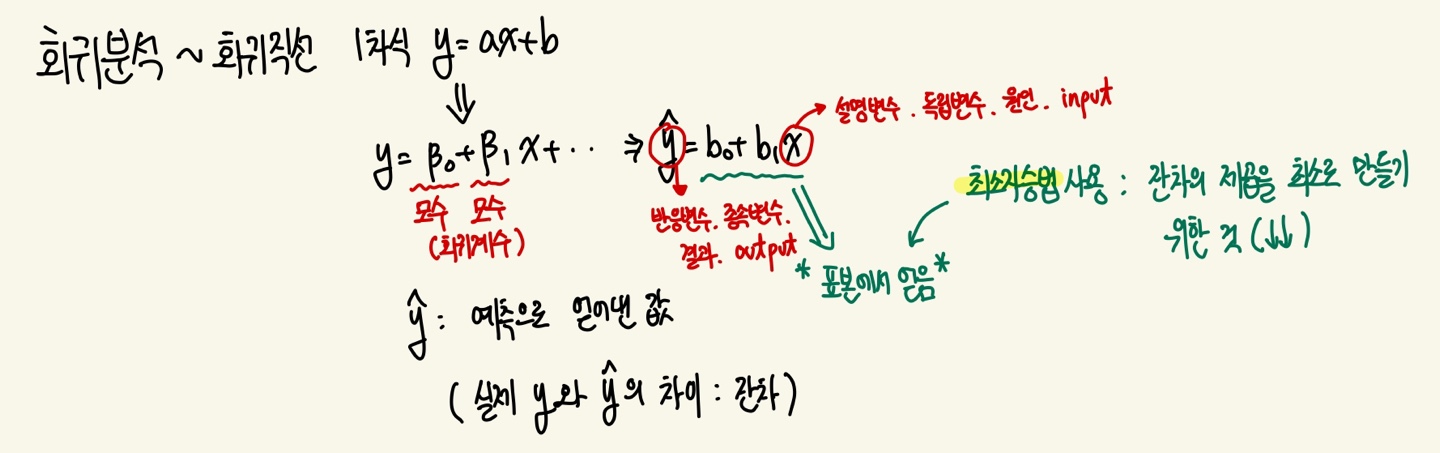
상관분석
- 지도학습 : 종속변수, 독립변수
- 비지도학습 : 변수의 구분이 없다.
- 모집단에서 랜덤 샘플링해서 표본의 상관계수로 모집단의 상관계수 추정 및 검정하는 것
회귀분석
- 지도학습 (관리학습) : 변수구분 (종속, 독립)
- 지도학습 1) 단순선형회귀 : 독립변수 1개
- 지도학습 2) 다중선형회귀 : 독립변수 여러 개
- 비지도학습 (비관리 학습, 자율학습) : 변수구분X
회귀분석에서의 b0, b1을 찾았다면 적합 (fitting)
- 계수검정 : 회귀계수 검정
- 모형검정 : 모형 (식) 전체 검정 → 모형 사용

회귀식의 설명력
- r : 상관계수
- r제곱 : 결정계수, 회귀식의 data설명력, 회귀식이 얼마나 데이터를 잘 표현했는가를 보여준다.
[ 6주차의 핵심 : 오즈비, 로지스틱 회귀 분석 ]
[ 시험문제 출제 : 빅데이터의 정의 및 개요, 하둡의 구성 ]

- 상관분석 : 모델링 X, 추정 및 검정
- 회귀분석 (Regression) : 수치형 데이터를 이용하여 분석한다. Input으로 수치형 데이터를 넣으면, Output으로 수치형 데이터 또는 문자형 데이터 (Good = 1, Bad =0) 으로 나온다.
- 이 식을 우리는 모델이라 부르며 이 과정을 모델링이라고 한다.
- 모델링이란 ? 예측함수를 생성하는 것이다. 독립변수와 종속변수를 가지고 계수들을 추정한다.
- 1. B0, B1의 추정 2. b0, b1의 신뢰성 및 타당성 검정 3. 모델의 타당성 검정
- 로지스틱회귀분석 (비선형)
- 판별분석

[ ★ 매우 중요, 시험 출제 ]
오즈비 : 성공확률과 실패확률의 비, 실패에 대한 성공의 확률, 1-p에 대한 p의 확률


로지스틱 회귀계수는 DB의 확률표본에 의하여 계산한다.
- 1. 계수검정 → t-검정 (이유: t분포하는 데이터라고 가정하는 것)
- 2. 모형검정 → F-검정 (모형검정, 모형 적합도 검정)
- 3. 새로운 데이터 적용
z의 크기 변화는 특정 계수만큼의 변화이다. 그 이유는 특정 계수가 기여도를 의미하기 때문이다.

로지스틱회귀는 S곡선으로 이루어져 있으며 비선형회귀분석이다. p(성공할 확률) (이)가 0.5보다 같거나 크면 1로 판정하고, 0.5보다 작으면 0으로 판정한다.
'빅데이터 분석 > 수업 필기' 카테고리의 다른 글
| 빅데이터분석 필기 (8) (0) | 2024.04.21 |
|---|---|
| 빅데이터분석 필기 (7) (0) | 2024.04.21 |
| 빅데이터분석 필기 (5) (0) | 2024.04.21 |
| 빅데이터분석 필기 (4) (0) | 2024.04.21 |
| 빅데이터 분석 필기 (3) (0) | 2024.04.21 |