



[2023 기출] 통계분석 시에 데이터에 대해 표준화를 해야 하는 두 가지 이유에 대하여 설명하시오.
- 표준화를 하지 않으면 영향력(크기)를 나타내지 못한다.
- 표준화를 통해 모든 변수의 평균을 0, 표준편차를 1로 맞추면 동등한 영향을 주도록 할 수 있다.
- 데이터의 크기에 영향을 받는다는 문제가 있기 때문이다.
- 표준화를 하지 않으면 모델의 학습이 왜곡될 수 있다.

[2023년 기출] 집단의 특성에 대한 추정이나 검정을 할 때 항상 유의수준을 기준하여 판정한다.
이때의 유의수준의 의미에 대하여 설명하시오.
- 유의수준이란, 통계량을 이용한 통계적 판정 결과가 틀릴 가능성이다. 다른 의미를 갖는다라고 보는 기준이다.
- 유의확률은 귀무가설의 통계량 값으로, 계산한 검정통계량 값에 해당되는 확률이다.
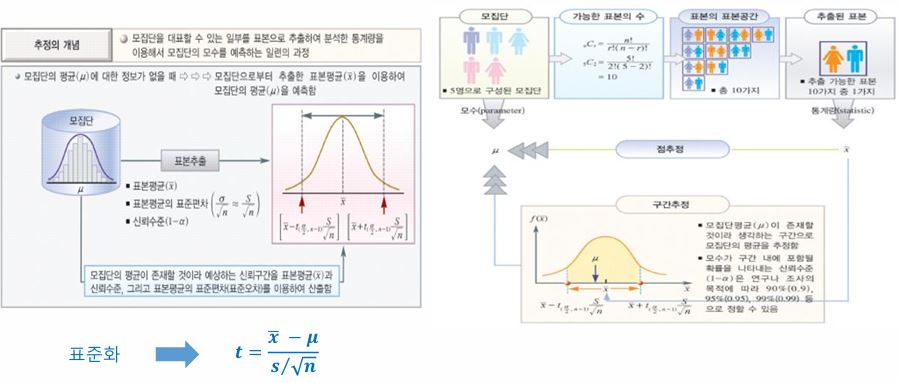
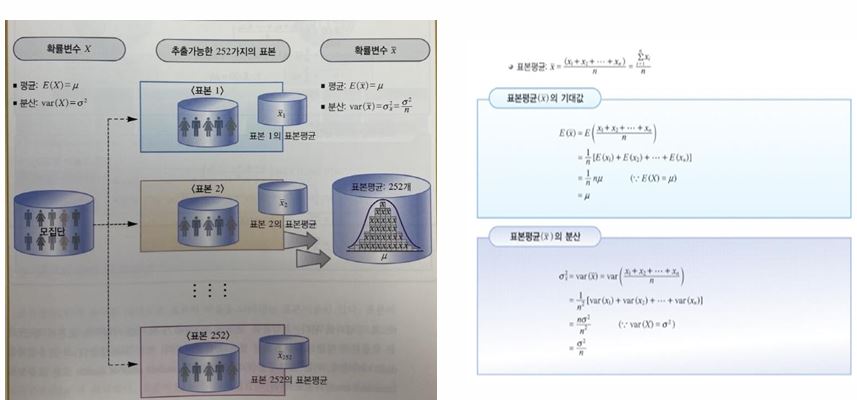
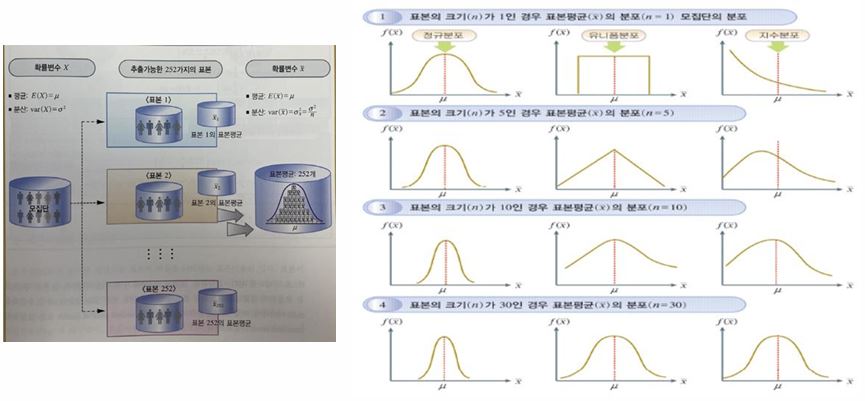
[시험 출제 유력] 추정의 개념에 대해 쓰시오.
- 모집단을 대표할 수 있는 일부를 표본으로 추출하여 분석한 통계량을 이용해서 모집단의 모수를 예측하는 일련의 과정이다.
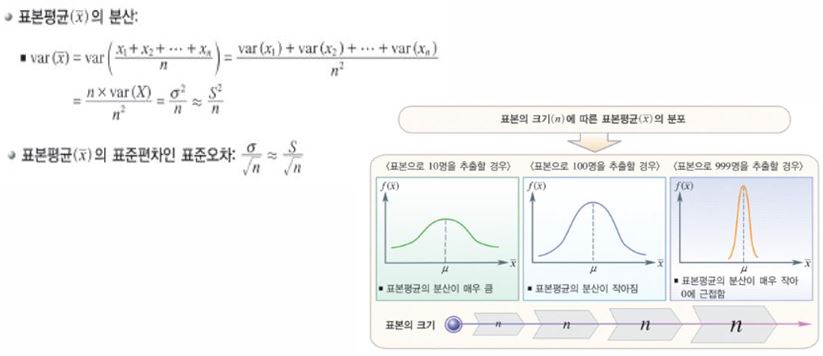
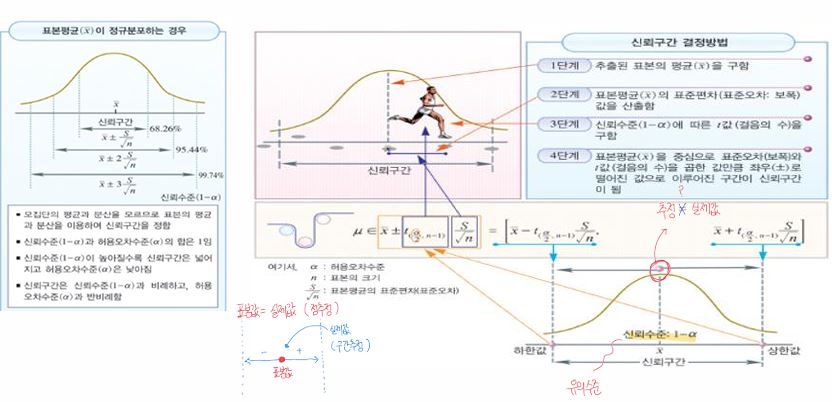

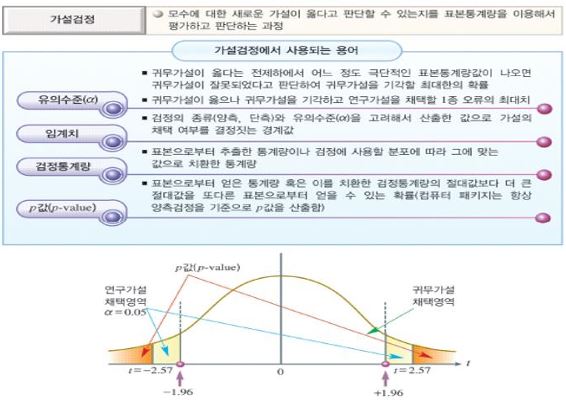
[시험 출제 유력] 검정의 개념에 대해 쓰시오.
- 모수에 대한 새로운 가설이 옳다고 판단할 수 있는지를 표본통계량을 이용해서 평가하고 판단하는 과정


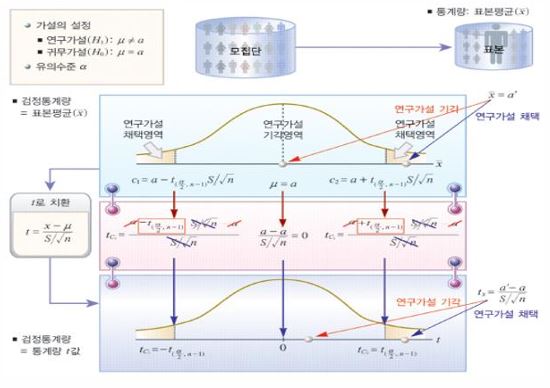



★ 연관성분석 : 2개 변수들 간의 연관성을 파악하는 분석방법


★ 교차분석 : 명목(서열)척도로 측정된 두 변수(특성, 요인) 간의 상호연관성을 알아보기 위한 분석
[시험 출제 유력] 교차분석을 왜 하나?
- 집단의 특성을 객관적으로 파악하기 위해서 한다. 다른 말로는, (정량적인) 평균과 분산과 같은 집단의 특성을 파악하기 위해서 한다.



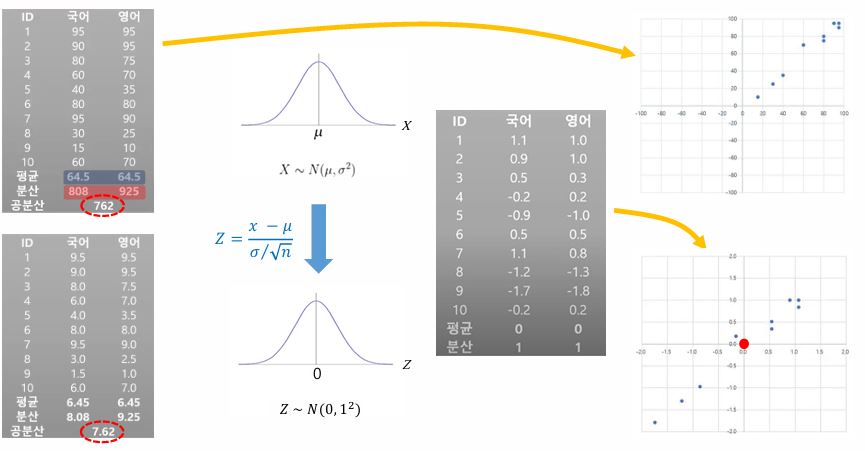
[2023년 기출] 상관계수와 공분산의 관계에 대하여 설명하시오.
- 공분산은 2개의 변수(X, Y) 간의 서로에 미치는 영향력을 의미한다. X의 편차와 Y의 편차를 곱한 값들의 평균으로, 데이터에 따라 공분산의 크기가 달라진다.
- 상관계수는 공분산을 표준화한 값이고, 두 변수 간의 선형적인 관계의 강도와 방향을 나타내는 값이다.
'머신러닝을 위한 통계학2 > 수업 필기' 카테고리의 다른 글
| 머신러닝을 위한 통계학2 6주차 (0) | 2024.10.28 |
|---|---|
| 머신러닝을 위한 통계학2 5주차 (0) | 2024.10.28 |
| 머신러닝을 위한 통계학2 3주차 (0) | 2024.10.28 |
| 머신러닝을 위한 통계학2 2주차 (0) | 2024.10.27 |
| 머신러닝을 위한 통계학2 1주차 (1) | 2024.10.27 |