
- library(MASS) : MASS 라이브러리를 로드
- library(car) : car 패키지를 로드합니다. 이 패키지는 선형 회귀 모델에 대한 다양한 진단 도구를 제공, vif 함수가 대표적
- library(skimr) : skimr 패키지를 로드합니다. 이 패키지는 데이터셋을 빠르게 요약하고 분석하는 기능을 제공
Boston 데이터셋을 로드한다. 이 데이터는 보스턴 지역의 주택 가격과 관련된 변수를 포함한 데이터셋이다. 그 이후, Boston 데이터셋을 df라는 데이터프레임에 저장한다. 이는 이후 코드에서 더 쉽게 참조하기 위해서이다.



skim함수를 사용해서 df 데이터프레임의 요약 통계를 표시한다. 이는 데이터의 분포, 결측값, 변수 유형 등을 간단하게 요약하여 보여준다.

initial_predictors 변수에 사용할 초기 예측 변수를 문자열 벡터로 저장한다. 이 변수들은 주택 가격을 예측할 때 사용하는 독립 변수들이다. medv (주택 가격)를 종속 변수로 하고, initial_predictors의 변수를 독립 변수로 한 선형 회귀 모델을 적합하다. lm 함수는 선형 회귀 모델을 생성한다.

앞서 생성한 선형 회귀 모델의 결과를 출력한다. 회귀 계수, p-값, R-제곱값 등의 정보를 확인할 수 있다.


VIF(Variance Inflation Factor, 분산 팽창 계수) 값을 계산한다. VIF는 회귀 모델에서 다중 공선성 문제를 확인하기 위해 사용되며, 값이 10을 넘으면 다중 공선성이 존재할 가능성이 높습니다. 계산된 VIF 값을 출력한다. 각 독립 변수에 대한 VIF 값을 보여준다.

VIF 값이 7보다 작은 변수를 선택한다. 다중 공선성 문제가 있는 변수를 제외하기 위해 이 값을 사용한다.

선택된 예측 변수 목록을 출력한다. VIF 값이 낮아 다중 공선성 문제가 덜한 변수를 포함한다.

- caret 패키지를 설치한다. caret 패키지는 머신러닝 모델의 훈련과 평가에 도움을 주는 여러 함수들을 제공한다.
- caret 패키지를 로드
- set.seed(123) : 난수 생성의 시드를 설정하여 결과의 재현성을 확보
- createDataPartition 함수는 medv 변수를 기준으로 데이터를 훈련 세트와 테스트 세트로 분할하는 데 사용된다. 여기서 p = 0.8은 데이터의 80%를 훈련 세트로 사용하겠다는 의미이다. list = FALSE는 반환 형식을 행 번호가 담긴 벡터로 지정한다.



- train_indices에 해당하는 행을 선택하여 df_train에 훈련 데이터를 저장한다. 이는 전체 데이터셋 중에서 80%의 데이터를 훈련 세트로 할당하는 과정이다. train_indices를 제외한 나머지 행을 선택하여 df_test에 테스트 데이터를 저장한다. 이는 나머지 20%의 데이터를 테스트 세트로 할당하는 과정이다.


- 훈련 데이터 df_train에서 선택한 예측 변수들만 추출하여 X_train에 저장한다. 이때 selected_predictors는 다중 공선성이 적은 변수들이 들어 있다.
- y_train <- df_train$medv : 훈련 데이터의 medv(주택 가격) 변수를 추출하여 y_train에 저장한다. 이는 종속 변수이다.

- 테스트 데이터 df_test에서 선택한 예측 변수들만 추출하여 X_test에 저장한다. 이는 테스트 세트의 독립 변수들이다.
- 테스트 데이터의 medv 변수를 추출하여 y_test에 저장한다. 이는 테스트 세트의 종속 변수이다.

- X_train 데이터에 절편 항(상수값 1)을 추가한다. cbind(1, as.matrix(X_train)) 는 모든 데이터 행에 첫 번째 열로 1을 추가하는데, 이는 회귀 모델에서 절편(intercept)을 포함하기 위한 것이다.
- y_train 값을 숫자형으로 변환한다. 이 단계는 회귀 분석을 수행할 때 필요한 변환이다.

- X_test 데이터에도 훈련 데이터와 동일하게 절편 항(1)을 추가한다. 회귀 모델에서 절편을 고려하기 위한 동일한 처리이다.
- y_test 값을 숫자형으로 변환한다. 이 역시 테스트 데이터를 분석할 때 필요한 변환이다.


- beta 변수는 회귀 모델의 베타 계수(회귀 계수)를 저장하는 벡터입니다. 여기서는 처음에 모든 계수를 0으로 초기화한다. ncol(X_train)은 독립 변수의 개수를 반환하는데, 독립 변수마다 하나의 베타 값이 존재하므로 그 개수만큼 0으로 초기화된 벡터를 생성합니다.

- 이 함수는 경사하강법(Gradient Descent)을 사용하여 선형 회귀 모델의 베타 계수(회귀 계수)를 최적화하는 과정을 구현한 것이다.
- X : 독립 변수 행렬 (데이터)
- y : 종속 변수 벡터 (실제 값)
- beta : 베타 계수 벡터 (초기값은 0으로 설정)
- learning_rate : 학습률 (경사하강법에서 매번 업데이트되는 크기)
- num_iterations : 반복 횟수 (경사하강법이 몇 번 반복될지 결정)
- m은 독립 변수 행렬 X의 행 수를 저장한다. 이는 데이터 포인트(샘플)의 수를 나타낸다. 회귀 모델에서는 데이터 포인트 수가 중요하다.
- cost_history는 반복마다 비용 함수 값을 저장하기 위한 벡터, 각 반복에서 비용 함수 값을 기록
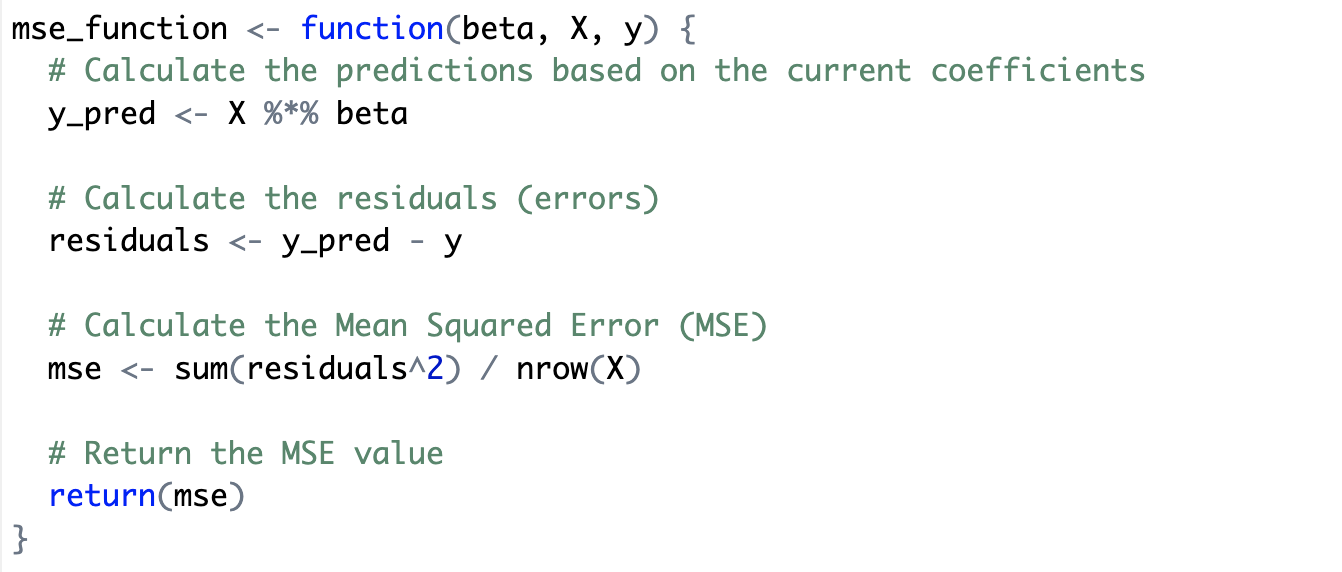
- 이 코드는 Mean Squared Error (MSE, 평균 제곱 오차) 를 계산하는 함수
- MSE는 회귀 모델의 예측 성능을 평가하는 지표 중 하나로, 예측값과 실제값 사이의 오차 제곱의 평균을 구하는 방식이다.
- beta : 회귀 모델의 계수(베타 값) 벡터
- X : 독립 변수 행렬 (데이터)
- y : 종속 변수 벡터 (실제 값)
- 이 함수는 현재 베타 값을 이용해 예측 값을 구하고, 이를 통해 MSE를 계산한다.
- y_pred는 현재 beta 값을 이용하여 예측된 값을 계산한다. 독립 변수 X와 베타 값 beta를 행렬 곱셈(%)으로 계산하여 모델이 예측하는 결과를 얻는다.

- 이 코드는 경사 하강법(Gradient Descent)을 사용하여 최적의 회귀 계수를 찾고, 그 과정에서 비용 함수의 변화를 시각화하는 과정
- learning_rate는 학습률, 경사 하강법에서 각 반복(iteration)마다 베타 값을 얼마나 크게 업데이트할지 결정하는 중요한 하이퍼파라미터이다.
- num_iterations는 경사 하강법의 반복 횟수, epoch이다. 10,000번의 반복을 설정하여 충분히 베타 값이 최적화되도록 한다.

- gradient_descent 함수를 호출하여 경사 하강법을 실행
- 이 함수는 X_train (훈련 데이터), y_train (종속 변수), beta (초기 베타 값), learning_rate (학습률), num_iterations(반복 횟수)을 인자로 받아 경사 하강법을 수행하고 최종 베타 값을 계산


- 경사 하강법을 통해 도출된 최종 beta 값을 final_beta에 저장한다.
- 이 값은 여러 번의 반복을 통해 학습된 최적의 회귀 계수이다.

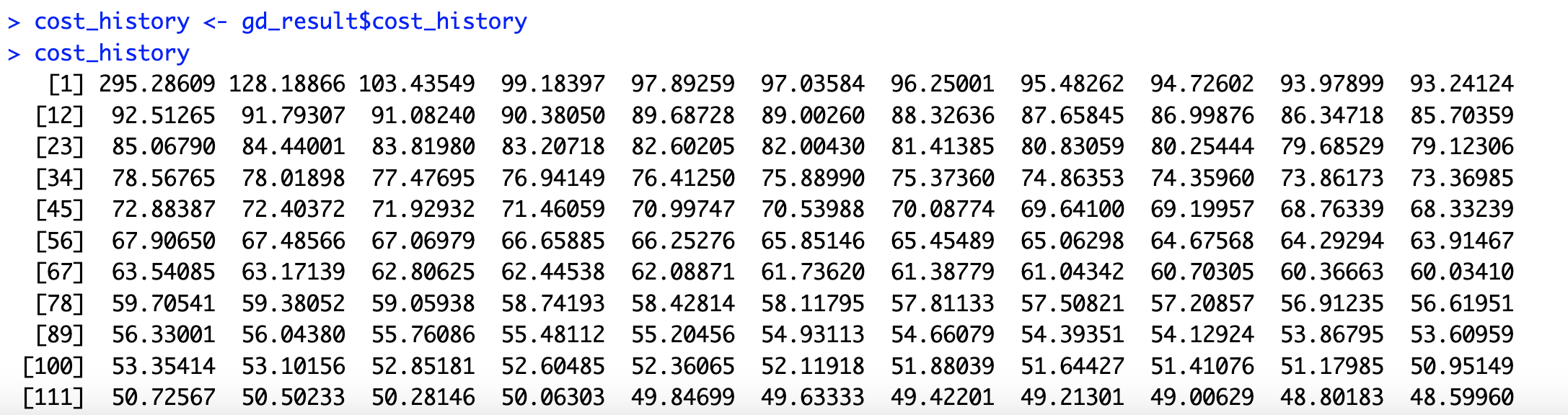
- 경사 하강법 실행 동안 각 반복에서 계산된 비용 함수 값들의 기록을 cost_history에 저장한다. 이 값들은 비용 함수가 경사 하강법을 통해 점차 줄어드는 과정을 보여준다.
- 비용 함수의 변화를 출력하여, 반복 횟수에 따라 비용이 어떻게 줄어드는지를 확인할 수 있다.

- plot 함수를 사용하여 경사 하강법 동안 비용 함수가 변화하는 그래프를 그린다.


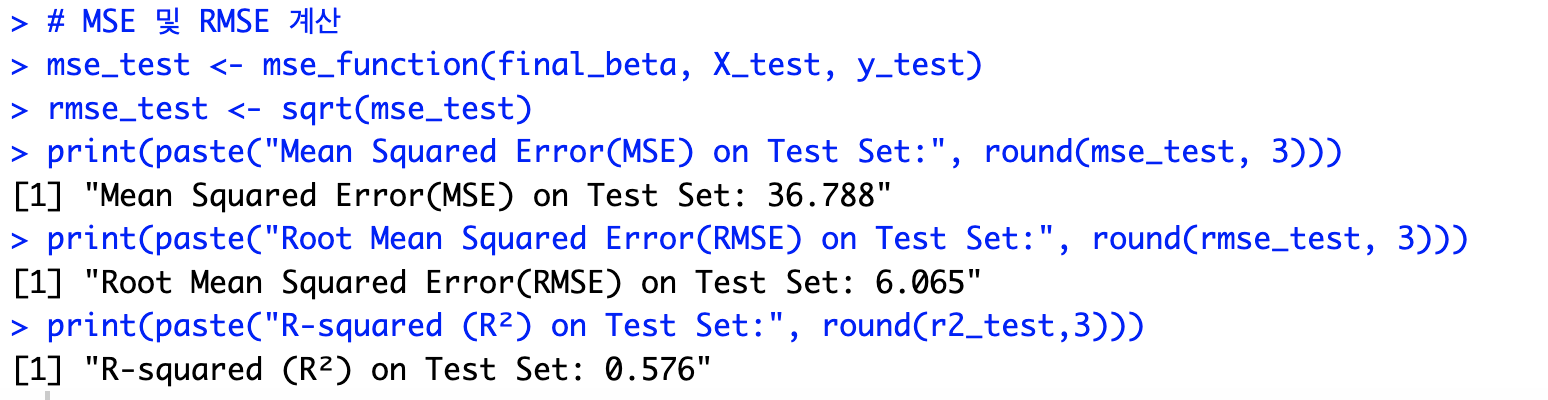
- 이 코드는 경사 하강법으로 학습된 모델을 사용해 테스트 데이터에 대한 예측 값을 계산하고, 잔차 제곱합, 총 제곱합, 결정 계수 (R²), 그리고 평균 제곱 오차(MSE)와 제곱근 평균 제곱 오차(RMSE)를 구하는 과정을 보여준다.
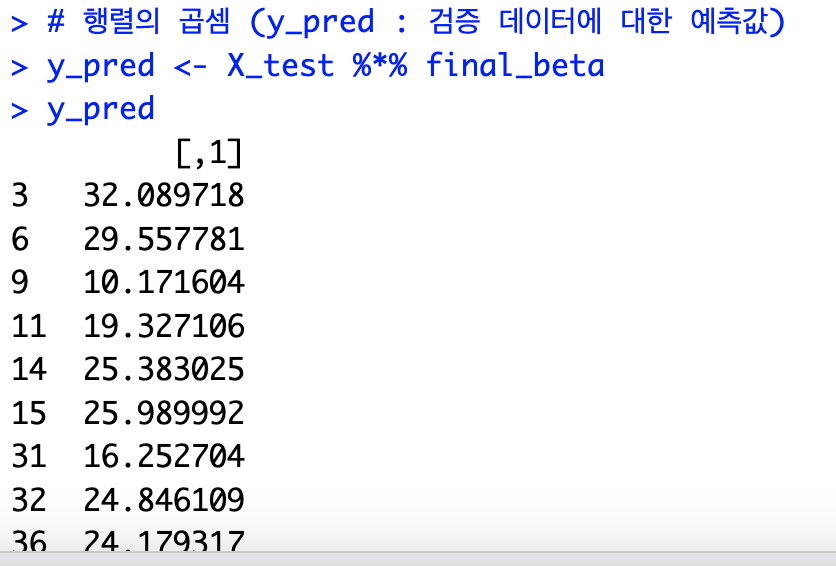
- y_pred는 테스트 데이터에 대해 final_beta를 사용하여 예측한 값이다. X_test (테스트 데이터)와 final_beta (최종 회귀 계수)를 행렬 곱셈(%)을 통해 계산하여, 모델이 예측한 종속 변수 값을 구한다.


- ss_res는 잔차 제곱합(Sum of Squared Residuals)
- 모델이 얼마나 오차가 있는지를 측정한다.
- 잔차가 클수록 모델의 성능이 떨어진다는 것을 의미한다.


- ss_total은 총 제곱합(Total Sum of Squares)
- 총 제곱합은 데이터의 분산을 나타내며, 모델 없이 단순히 평균으로 예측했을 때의 오차를 나타낸다.
- 전체 데이터에서 예측 없이 평균으로 예측했을 때의 총 오차를 나타낸다.


- r2_test는 결정 계수(R², R-squared)
- 결정 계수는 모델이 얼마나 데이터를 잘 설명하는지를 나타내며, 값이 1에 가까울수록 모델이 잘 설명하는 것

- mse_test는 테스트 데이터에 대한 평균 제곱 오차(MSE, Mean Squared Error)
- rmse_test는 제곱근 평균 제곱 오차(RMSE, Root Mean Squared Error)

- 이 코드는 학습된 모델을 저장하고, 이를 불러와 새로운 데이터를 사용해 예측하는 과정
- save 함수는 주어진 객체를 파일로 저장
- 여기서는 학습된 final_beta(최종 베타 값)와 selected_predictors(선택된 예측 변수들)를 "final_model.RData"라는 파일에 저장한다.


- df_test 데이터에서 selected_predictors에 해당하는 열만 추출하여 new_data에 저장한다.
- 즉, 모델에서 사용할 예측 변수들만 추출한다.

- X_new는 새로운 데이터를 모델의 입력 형식에 맞게 변환한 것이다.
- cbind(1, as.matrix(new_data))는 각 데이터 행에 절편 항(상수 값 1)을 추가한 것이다. 회귀 모델에서 절편을 포함하기 위해 이 과정이 필요하다.

- y_new_pred는 학습된 베타 값(final_beta)을 사용하여 새로운 데이터에 대한 예측 값을 계산한 것이다.
- X_new와 final_beta의 행렬 곱셈(%)을 통해 예측 값을 얻는다.
- 이 결과는 모델이 새로운 데이터에 대해 예측한 종속 변수 값이다.
- y_new_pred에 저장된 예측 결과를 출력한다. 이 값들은 모델이 새로운 데이터에 대해 예측한 결과이며, 각각의 데이터 포인트에 대해 예측된 주택 가격이다.
'머신러닝2 > 수업 필기' 카테고리의 다른 글
| 머신러닝2 11주차 (0) | 2024.12.11 |
|---|---|
| 머신러닝2 10주차 (0) | 2024.12.11 |
| 머신러닝2 7주차 (1) (0) | 2024.10.23 |
| 머신러닝2 5주차 (0) | 2024.10.23 |
| 머신러닝2 4주차(2) (0) | 2024.10.23 |