
- MSR : 회귀의 평균 제곱 → 회귀모델이 설명하는 변동성을 나타낸다.
- MSE : 오차의 평균 제곱 → 회귀모델이 설명하지 못하는 변동성을 나타낸다.
- F = MSR/MSE


- RMSE : 오류 지표를 실제 값과 유사한 단위로 변환하여 해석을 쉽게 변환한다.
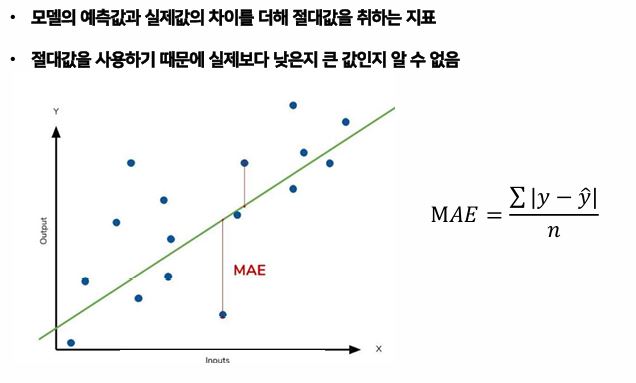
- MAE : 모델의 예측값과 실제값의 차이를 더해 절댓값을 취하는 지표
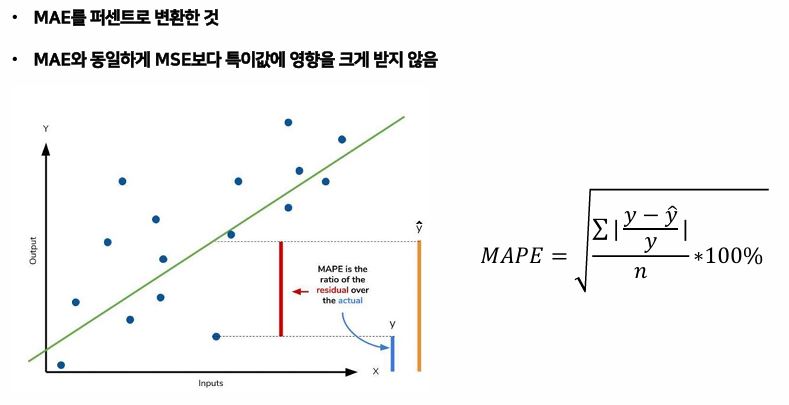
- MAPE : MAE를 퍼센트로 변환한 것이다.
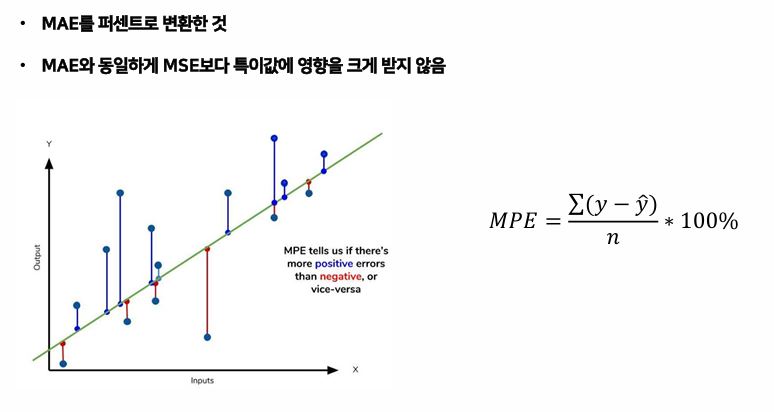
- MPE : MAPE에서 절댓값을 제외한 지표이다. 퍼센트로 변환한 것은 맞다.
- 더 관련된 것은, [Python] 성능 측정 지표 :: MAE, MSE, RMSE, MAPE, MPE, MSLE 여기를 참고하길 바란다.

- R-Squared : 모델의 독립변수에 의해 설명되는 종속변수의 분산비율을 측정한다
- → 종속변수의 변화를 잘 설명했는지를 판단한다. 즉, 모형이 예측값을 잘 이해하는지와 같은 설명력으로 볼 수 있다.
- RMSE : 예측값과 실제값 간의 차이를 측정하여 모델이 데이터에 얼마나 잘 맞는지를 판단하는 것이다.
- → 예측력으로 볼 수 있다.

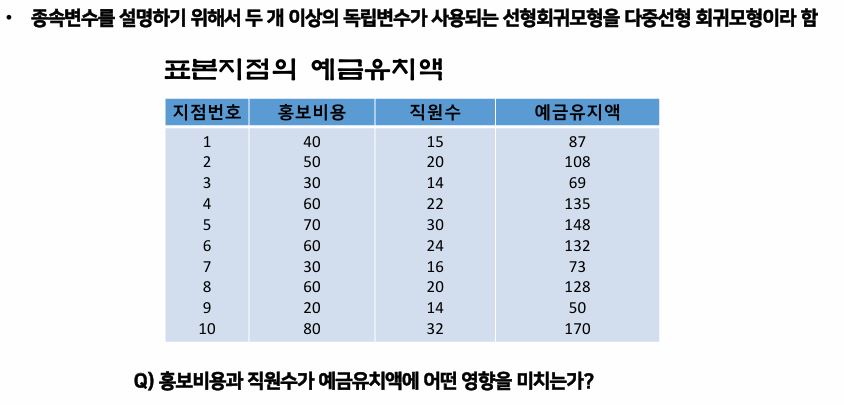
- 종속변수를 설명하기 위해서 두 개 이상의 독립변수가 사용되는 선형회귀모형을 다중선형회귀모형이라고 한다.
- 종속변수로는, 명목형 변수와 연속형 변수가 있고 모델의 목적은 표본 내에서의 오차인 잔차를 줄이는 것이다.
- → SSE를 줄이는 것이다.

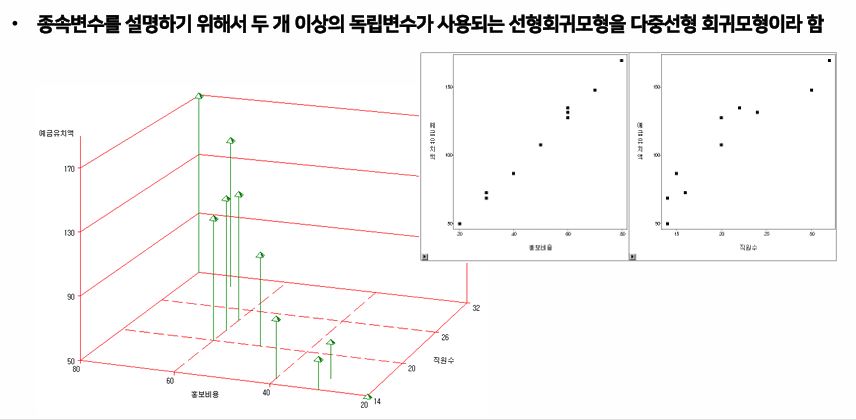

다중선형회귀를 왜 하냐? WHY?
- 초평면에 대해 설명해야 하기 때문이다.
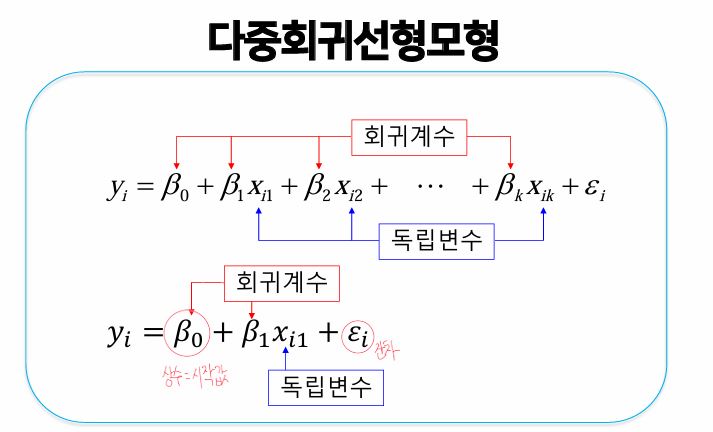

[여기서부터가 시험문제에서 핵심이 될 파트이니, 잘 보도록 하자.]
diabetes 데이터 : 당뇨병 데이터

- check.for.updates.R() : R버전을 확인하는 코드이다.
- install.R() : R버전을 업데이트하는 코드이다.

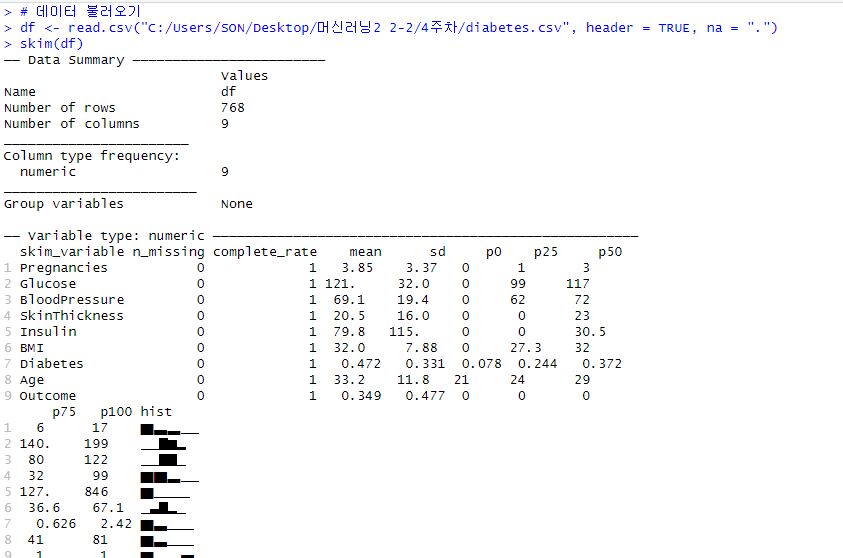
- header = TRUE : 첫 번째 행이 열 이름(컬럼명)으로 사용된다는 것
- na = "." : 데이터에서 결측치(NA)를 특정 기호로 처리하도록 설정하는 옵션, 여기선 결측치를 . 으로 설정
- skim() : 데이터 프레임을 요약해서 보여주는 함수


- as.factor( ) : 하나의 변수의 자료형을 요소형으로 바꾸는 함수


- mutate_if( ) : 특정 조건을 만족하는 변수(컬럼)에만 변형을 적용할 수 있도록 도와준다.
- → 데이터 프레임의 모든 변수에 변형을 적용하는 대신, 조건을 만족하는 변수들에만 변형을 적용할 때 사용



여러 개의 종속변수라던가, 여러 개를 삭제하고 싶다면?


열이 없기 때문에 삭제가 진행되지는 않았다.



- lm(df$Diabetes ~ ., data=df) : 종속 변수 Diabetes를 모든 독립 변수로 예측하는 선형 회귀 모델을 만든다.
- lm(df$Diabetes ~ 1, data=df) : 1은 절편만 있는 모델을 의미한다. 즉, 독립 변수가 없는 모델을 만든다. 이 모델은 Diabetes 값의 평균만을 예측한다.

두 집단이 의미있는 차이가 있다는 것을 알았다. → 독립변수가 효과가 있다는 얘기이다.


- tidy() : 모델의 결과를 깔끔한 형태의 데이터 프레임으로 변환하는 데 사용
- → R의 다양한 모델링 함수는 보통 복잡한 형식의 출력을 내놓는데, 이를 정리된 형태의 데이터 프레임으로 만들어 분석이나 시각화를 더 쉽게 할 수 있도록 도와주는 역할을 한다.

- glance() : 모델의 전체적인 요약 통계를 하나의 행으로 반환하는 함수
- 모델의 전반적인 성능을 평가하는 데 유용한 메트릭들을 포함한 단일 행의 데이터 프레임을 반환
- 이 함수는 모델 전체에 대한 정보를 요약적으로 제공하며, 개별 변수나 계수에 대한 정보는 포함X
해석 결과를 쓰자면, r.squared (결정계수) 는 0.0629를 나타내고 있다. 이 말은, 회귀 모델이 전체 데이터 변동의 약 6.29%를 설명한다는 의미이다. 이 값이 낮다는 것은 모델이 데이터를 잘 설명하지 못하고 있음을 의미이다.
adj.r.squared (수정된 결정 계수) 또한 0.0542이다. 독립 변수의 수와 표본 크기를 고려한 결정 계수인데, 여기서도 모델의 설명력이 약 5.42%로 낮다는 것을 알 수 있다. sigma (잔차 표준 편차)는 0.322이고, 모델의 잔차(오차)의 표준 편차를 말한다. 이 값이 클수록 데이터와 모델 간의 차이가 크다는 걸 의미한다. 이 외에 아래에 적어놓겠다.
- statistic (F 통계량) : 7.28
- 회귀 모델의 유의성을 평가하는 F-통계량
- 모델이 전체적으로 유의미한지를 판단하는 데 사용되며, p-value와 함께 해석해야 한다.
- p.value : 1.80e-8 (즉, 0.000000018)
- p-value는 매우 낮은 값으로, 통계적으로 유의미한 결과
- 즉, 이 모델이 우연에 의한 결과일 가능성은 매우 적다.
- df (자유도) : 7
- 모델에 사용된 자유도의 수
- logLik (로그 가능도) : -216
- 로그 가능도는 모델의 적합도를 평가하는 지표 중 하나로, 값이 낮을수록 모델이 데이터를 잘 설명하지 못하고 있을 가능성이 있다.
- AIC (Akaike Information Criterion) : 450
- AIC는 모델 간의 성능을 비교할 때 사용되는 지표로, 값이 낮을수록 더 좋은 모델을 의미
- BIC (Bayesian Information Criterion) : 492
- BIC도 AIC와 비슷한 기능을 하지만, 모델에 사용된 변수를 더 많이 벌주기 때문에 AIC보다 더 엄격한 기준이다.
- deviance (편차) : 해당 결과에서는 표시되지 않았지만, 잔차와 관련된 정보이다.
- df.residual (잔차 자유도) : 결과에서 주어진 잔차의 자유도
- nobs (관측된 데이터 개수) : 데이터의 총 관측치 수
- 요약하자면, 이 회귀 모델은 통계적으로 유의미하긴 하지만, 설명력(결정 계수)이 낮아서 데이터를 충분히 설명하지 못하는 것으로 보인다.





[모형의 타당성 & 신뢰성 검정]
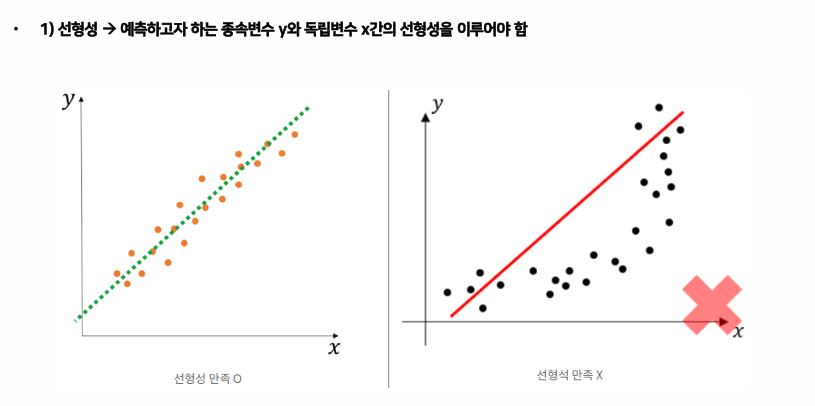
- 선형성 → 예측하고자 하는 종속변수 Y와 독립변수 X간의 선형성을 이루어야 한다.
- 등분산성 → 특정한 패턴 없이 고르게 분포해야 한다.
- 독립성 → 잔차 사이에는 상관관계가 없이 독립적이어야 한다. (변수들끼리 서로 영향을 주어선 안된다.)
- 정규성 → 잔차가 정규성을 만족하는지 여부
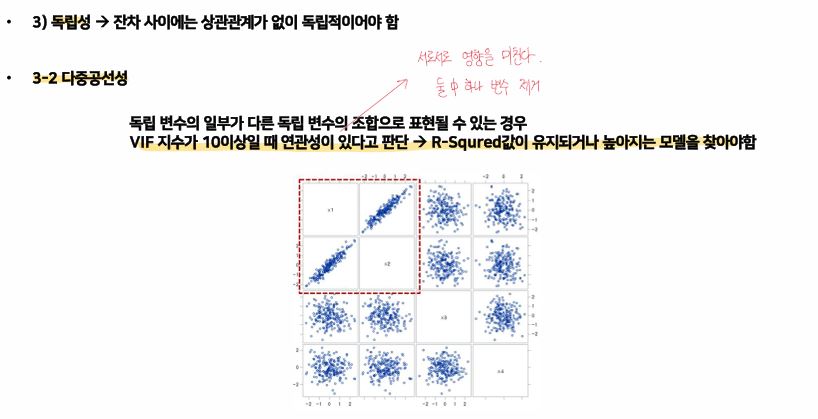
- 다중공선성 → 회귀 모델에서 두 개 이상의 독립변수가 서로 높은 상관관계가 있는 상황 → 하나 제거



독립성 검정
- Durbin Watson 검정 : 1.5 ~ 2.5 사이 일때 잔차는 독립이다.
- 다중공선성 → VIF 지수가 10이상이면 연관성이 있다고 판단하고 10이상인 것들은 제거한다.
- → R-Squared값이 유지되거나 높아지는 모델을 찾아야 한다.
다중공선성을 왜 제거해야 하나?
- 다중공선성이 확인이 되면, 계수를 신뢰할 수 없게 된다. 뿐만 아니라, 결과 해석하는 데에 어려움을 겪고, 과적합 현상이 발생할 수도 있다.


'머신러닝2 > 수업 필기' 카테고리의 다른 글
| 머신러닝2 7주차 (1) (0) | 2024.10.23 |
|---|---|
| 머신러닝2 5주차 (0) | 2024.10.23 |
| 머신러닝2 4주차(2) (0) | 2024.10.23 |
| 머신러닝2 2주차 (2) | 2024.10.22 |
| 머신러닝2 1주차 (1) | 2024.10.22 |