
- 주석 처리 : #
- 문자열을 출력하고 싶다면, " " 안에 문자열을 넣고 출력하는 함수는 print( )이다.
- print( ) : 출력, 두 문장을 한 문장에 이어 출력하고 싶다면 ( ; ) , 하지만 잘 사용하지 않는다.
- 도움말 : help( ), ?
- 함수의 사용법과 예시를 알고 싶다면, example( )
- install.packages(" ") : 디스크에 다운하는 작업
- update.packages(" ") : 기존에 있던 패키지를 업데이트하는 작업
- library( ) : 메모리에 올리는 작업
→ 사용 후, 메모리에 내려줘야 한다. 오른쪽에서 패키지에 들어가, uncheck해주면 된다. - 패키지 궁금한건 물음표 두개 (??)
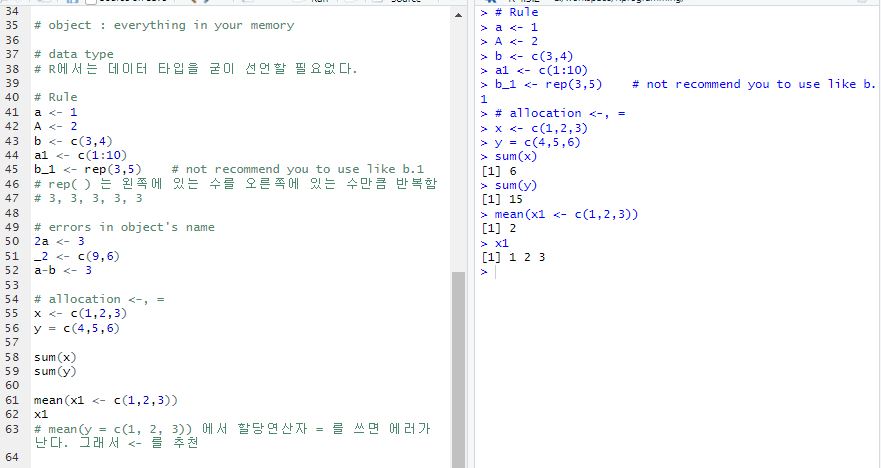
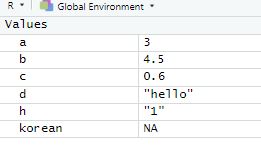
메모리에 있는 모든 것들은 object, 객체이다.
※ R에서는 데이터 타입을 굳이 선언할 필요없다. a1 ← c(1:10) 이렇게 대입하면 int 자료형으로 들어가지만, 일반적인 경우에는 다 num이다.
- 대입연산자 : ←, =
- mean(y = c(1, 2, 3)) 에서 할당연산자 = 를 쓰면 에러가 난다. 그래서 ← 를 추천
- rep( ) : 왼쪽에 있는 수를 오른쪽에 있는 수만큼 반복한다. 예시) 3, 3, 3, 3, 3
- sum( ) : 합을 출력해주는 함수
- 변수 이름을 설정할 때는, 앞에 숫자로 시작하거나, _로 시작하면 안된다. 변수명에 연산자가 있어서도 안된다.

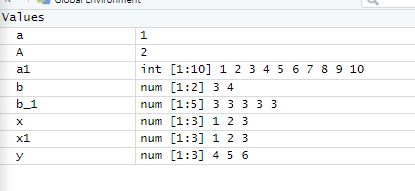
- ls( ) : 할당된 객체를 다 보여준다.
- → 객체가 없다면 출력 : character(0)
- rm( ) : 메모리에서 괄호 안에 있는 객체를 삭제, 쉼표( , )를 구분자로 여러 개 삭제 또한 가능하다.
- rm(list=ls( )) : 메모리에 담겨 있는 모든 객체들을 삭제한다.
- is.na ( ) : NA 이니? 물어보는 함수 / 아니면 FALSE , 맞으면 TRUE
- ★ NULL 과 NA의 차이는 ?
▶ NA는 메모리에 방을 만들어 놓지만, NULL은 객체만 만들고 방은 만들어 놓지 않는다.


- nchar( ) : 괄호안의 변수 문자열 수를 세어서 반환한다.
- substr( ) : 변수 인덱싱을 해주는 함수이다. (인덱싱 반환 ?)
- paste( ) : 문자열이랑 문자열을 붙이다.
- ※ 기본 디폴트는, 공백있이 붙인다. 공백없이 붙이고 싶다면 반드시, sep="" 조건을 추가해야 한다.
- paste0( ) : 공백없이 붙인다.


- %% : 나머지를 출력
- %/% : 몫을 출력
- / : 실수형 그대로 출력
- h ← "1"
※ h+1 : 문자랑 숫자랑 사칙연산이 불가능하다.h + 1에서 다음과 같은 에러가 발생했습니다:이항연산자에 수치가 아닌 인수입니다 - logical data : 논리값 (TRUE : 1, FALSE : 0) ; R언어에서는 대문자로 써줘야 한다.
- T랑 F는 예약어 이므로, 객체이름으로 사용하지 말자. 에러는 발생하지 않는다.
- &&, || 교환법칙 성립 된다, 교환 및 분배 및 드모르간 법칙 성립 된다. 집합의 개념과 동일하다.
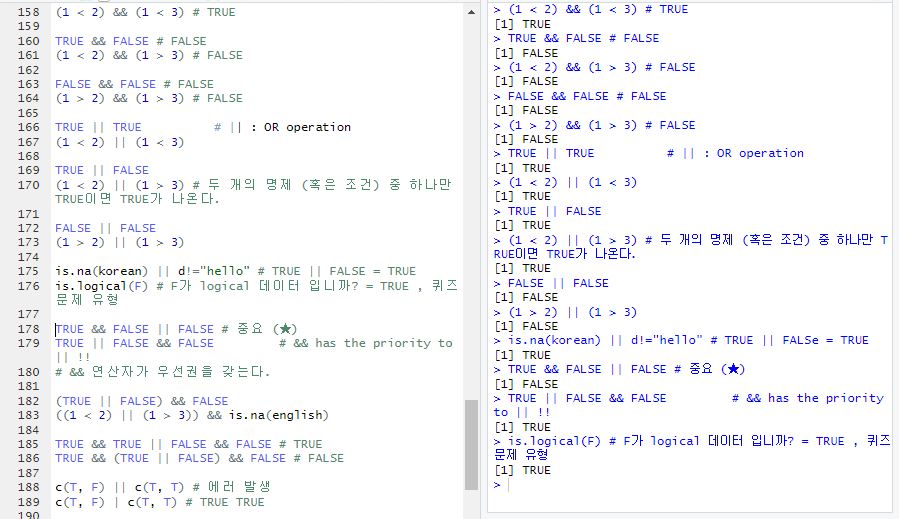
- || : 두 개의 명제 (혹은 조건) 중 하나만 TRUE이면 TRUE가 나온다. (OR operation)
- is.logical( ) : 괄호 안에 있는 것이 logical 데이터 입니까?
- ★ is.logical(F) # F가 logical 데이터 입니까? = TRUE , 퀴즈 문제 유형
- TRUE && FALSE || FALSE 중요 (★)
- → && 연산자가 || 연산자보다 우선권을 갖는다.
- c(T, F) || c(T, T) : 에러 발생
c(T, F) | c(T, T) : TRUE TRUE

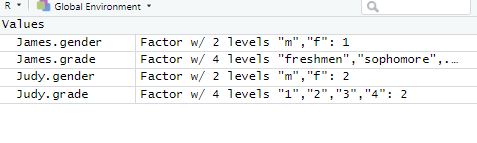
- Factor : 요소값(명목척도)
- nlevels( ) : 명목척도, 범위의 개수를 반환해준다.
- levels( ) : 어떠한 명목척도가 있는지 반환해준다. 예시) "m", "f"
- James.grade + Judy.grade 는 1 + 2인데 에러가 발생한다. 그 이유는 저 1과 2는 숫자를 나타내는 것이 아닌 명목척도(1학년, 2학년)을 나타내는 것이므로 사칙연산이 불가능하다.
- levels( ) ← c( ) 를 통해 명목척도(?)들의 이름을 바꿀 수도 있다.


- vector : collection of scalars
- ※ 벡터는 데이터 타입이 같아야 한다.
- names( ) : v 벡터의 요소값에 각각 이름을 붙여주는 함수
- names(v) ← c("a", "b", "c")
갯수가 맞지 않는다면, 남는자리는 <NA>로 처리가 된다.
▶벡터에서의 인덱싱과 슬라이싱 ?
- R언어에서는 예시로 v[-1]을 하면 뒤부터 출력이 아닌, 1번 방을 제외하고 출력하는 것이다.
- v[2:4] 는 2번째부터 4번째 출력이다.
- length(v) : 벡터의 길이를 반환해주는 함수이다.
- max(v) : 벡터 내의 최댓값 출력
min(v) : 벡터 내의 최솟값 출력 - which.max(v) : 제일 큰 값이 어느 방에 있니?
which.min(v) : 제일 작은 값이 어느 방에 있니? (방 위치 반환) - → v[which.max(v)] == max(v)


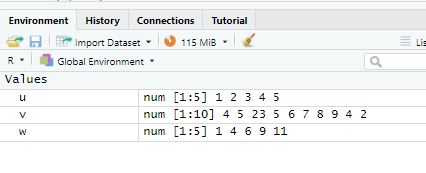
▶ 벡터의 연산 ?
- 벡터와 벡터끼리의 연산은, 같은 자리에 있는 것들끼리 계산이 되어진다.
- 자릿수가 맞지 않는다면 (차원이 같지 않다면), 경고가 뜨지만 계산은 된다.
(1 2 3 4 5) + (1 2 7) == (1 2 3 4 5) + (1 2 7 1 2)
→ 리싸이클링, 벡터의 차원 수가 맞지 않으면 리스트의 처음으로 돌아가 다시 사용! 퀴즈 출제 (매우 중요) - 벡터 %*% 벡터 : inner product (벡터의 내적, 자리에 맞게 곱셈을 한뒤, 덧셈)
- mean( ) : 평균 반환
- var( ) : 분산 반환
- sqrt( ) : squared root (루트) , 분산에 루트 = 표준편차
- sd( ) : 표준편차 반환
- identical( ) : 벡터 자체 두개를 비교, TRUE or FALSE 반환
- 벡터 == 벡터 : 벡터의 요소끼리 비교
- all(벡터 == 벡터) : 벡터 자체 두개를 비교, TRUE or FALSE 반환, identical( )


- intersect(u,w) : 교집합
- union(u,w) : 합집합
- setdiff(u,w) : 차집합 (u - w)
- setdiff(w,u) # 차집합 (w - u)
※ 당연한 얘기이지만, 집합 개념에서의 A-B != B-A - %in% : 집합에서의 E이다. 왼쪽 요소가 오른쪽 집합에 속하냐~?
- 두 벡터 안에 요소가 같아도, 두 요소의 순서가 다르면 두 벡터는 다르다고 나온다.


- seq( ) : 순열 생성하기
- [조건] by = ? : ?만큼 증가시켜 순열을 생성하라.
- by가 아니더라도, 예시로 y_1 ← seq(1, 12, 5) 라는 코드는 1부터 12까지 5만큼 증가시켜 순열을 생성하라는 의미
- y_2 ← seq(1, 12, length.out = 10) ; length.out = : 1부터 12까지 10개로 쪼개어, 똑같은 등분으로 나누는 것이다.
- rep(A, B) : A를 B만큼 반복해라, 문자(열)도 가능
- [조건] times : ~바퀴 (횟수)
- [조건] each : 각각
- append( ) : 붙이다
- → 숫자형 + 문자형 = 오류발생X, 하지만 숫자형이 문자형으로 자료형이 바뀐다.


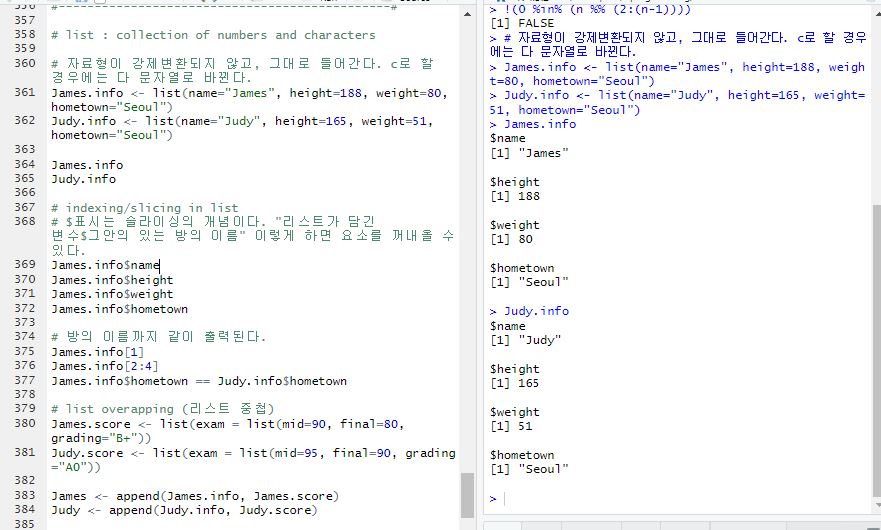
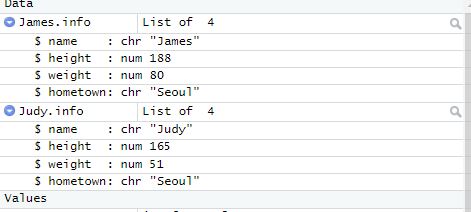
리스트 : collection of numbers and characters ( ← list( ) )
※ 자료형이 강제변환되지 않고, 그대로 들어간다. c로 할 경우에는 다 문자열로 바뀐다.
- $표시 : 슬라이싱의 개념이다. "리스트가 담긴 변수$그안의 있는 방의 이름" 이렇게 하면 요소를 꺼내올 수 있다.
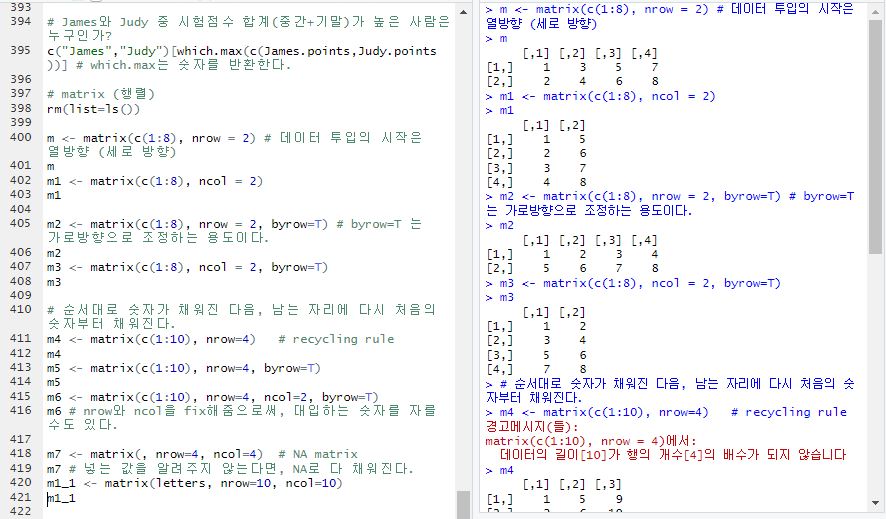
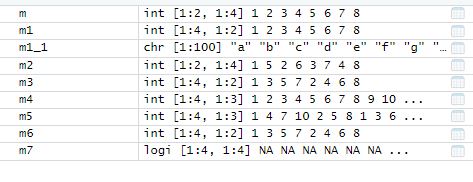
matrix : 행렬
- 데이터 투입의 시작은 열방향 (세로 방향), nrow는 행의 개수를 의미하며 ncol은 열의 개수를 의미한다.
- byrow=T : 가로방향으로 조정하는 용도이다. (bycol=T : 세로방향으로 조정하는 용도)
- 행렬에서의 데이터는 순서대로 숫자가 채워진 다음, 남는 자리에 다시 처음의 숫자부터 채워진다. (recycling rule)
- nrow와 ncol을 fix해줌으로써, 대입하는 숫자를 자를 수도 있다.
- m7 <- matrix(, nrow=4, ncol=4) : NA matrix
m7 → 넣는 값을 알려주지 않는다면, NA로 다 채워진다.


diagonal element in matrix
- I ← diag(4) : identity matrix (단위행렬)
- J ← diag(3,4) : 대각선 요소가 3인 4x4 대각행렬
- diag(A, B) : 오른쪽 값을 B라 할때 B*B 정방행렬로 왼쪽의 값 A들로 채워진다.
create a matrix using vectors
- rbind( ) : 행 결합 (행 아래에 붙는다)
- cbind( ) : 열 결합 (열 옆에 붙는다)