[학습목표]
이진 이미지 분류에 대해 이해하고 구글 코랩을 활용한 개와 고양이 분류 학습을 따라할 수 있다.

이번에 핵심 내용 : 이진 이미지 분류 (Image Binary Classification)






★ 배치처리 (매우 중요)
- 예시로, 1000장의 훈련용 데이터를 10장씩 나누면 100묶음이 된다. 이 100묶음을 다 1번 학습한 것이 1에폭이라고 부른다.
- 컴퓨터가 병목 현상이 발생하지 않도록 적절한 양의 데이터들을 묶어서 처리해 줌으로써 우리가 조금 더 효율적으로 그리고 시간을 단축해서 우리가 원하는 결과를 얻어낼 수 있기 때문에 데이터를 미니 배치 학습하는 것이 굉장히 큰 장점이 있다고 보면 된다.

배치 처리
- 이미지 1장당 처리 시간을 대폭 줄여주며 컴퓨터로 계산할 때 큰 이점을 준다.
- 수치 계산 라이브러리 대부분이 큰 배열을 효율적으로 처리할 수 있도록 고도로 최적화되어 있기 때문이다.
- 느린 I/O 를 통해 데이터를 읽는 횟수가 줄어, 빠른 CPU나 GPU로 순수 계산을 수행하는 비율이 높아진다.

훈련 데이터 VS 테스트 데이터
- 머신러닝 (기계학습 문제)에서는 데이터를 훈련 데이터와 테스트 데이터로 나눠 학습과 실험을 수행하는 것이 일반적이다.
- 훈련 데이터는 학습을 하여 최적의 매개변수를 찾는다.
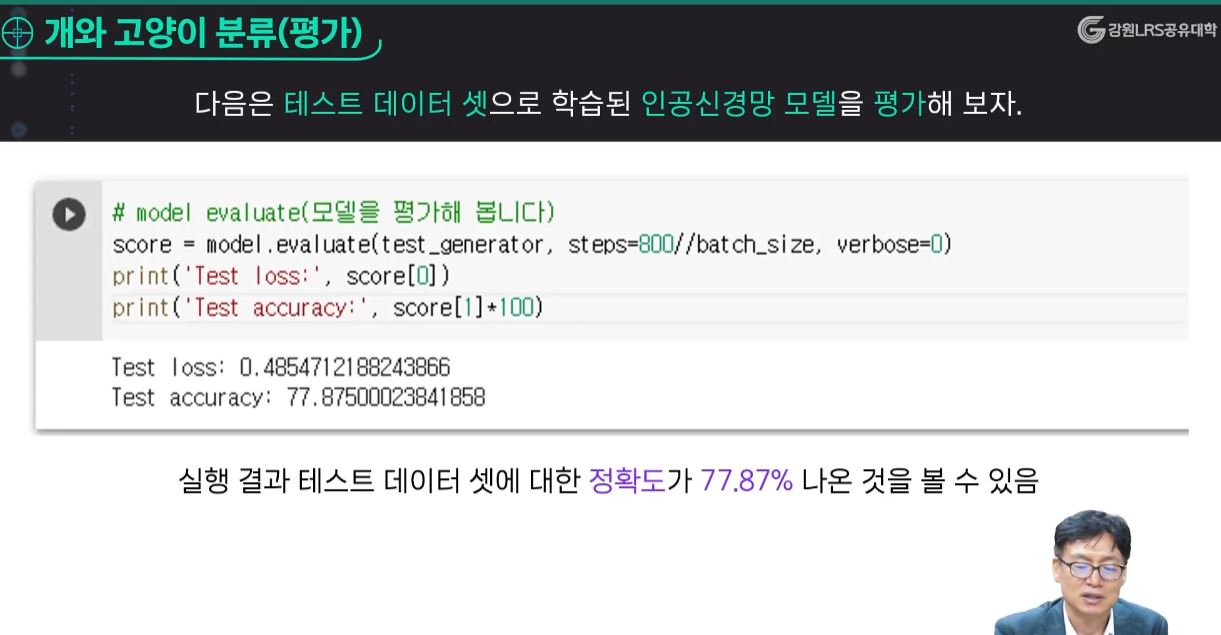
- 테스트 데이터는 훈련한 모델의 실력 및 성능을 평가한다.
- 왜 나눠야 할까? 우리가 원하는 것은 범용적으로 사용할 수 있는 모델이기 때문이다.
- 범용 능력이란, 아직 보지 못한 데이터로도 문제를 올바르게 풀어내는 능력이다. 범용 능력을 획득하는 것이 머신러닝의 최종 목표이다.
- 훈련용 데이터에만 너무 지나치게 학습을 하게 되고 새로운 어떤 데이터에 대해서는 검증 능력이 떨어지는 모델을 우리는 좋은 알고리즘이라고 안한다. → 과적합 발생
- 데이터를 적절하게 분리를 해서 학습을 시키고 평가하는 것은 매우 중요하다.

오버피팅
- 하나의 데이터 셋에만 지니차게 최적화된 상태를 말한다.




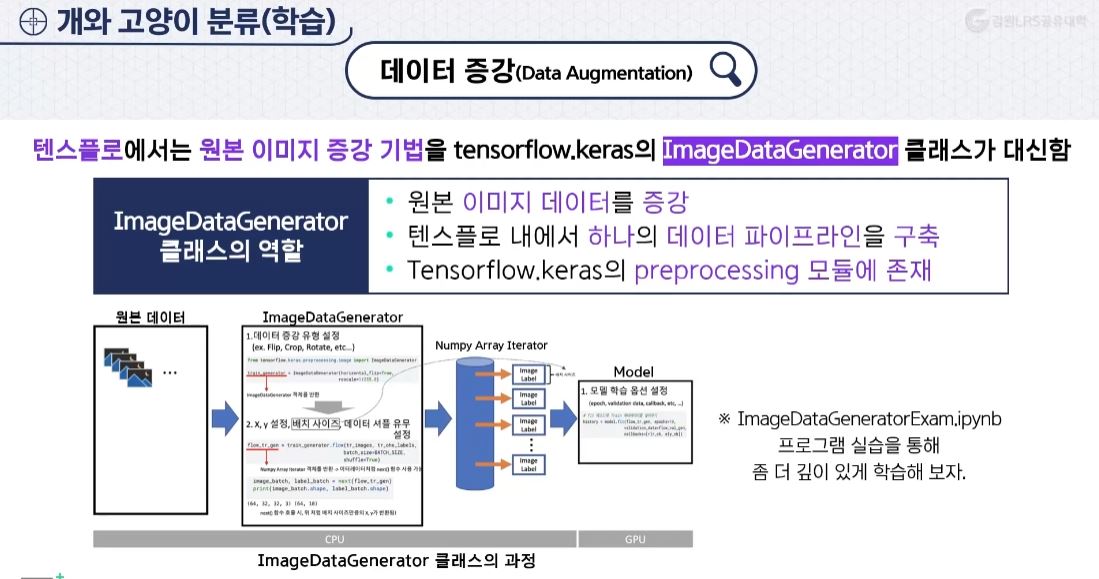
ImageDataGerator 클래스
- 데이터 증강을 지원한다.
- 파라미터 값 전달을 하여 → 데이터 정규화 과정을 한다.
- 왜 진행해? 데이터의 편향을 해결하기위해서, 데이터 증강을 한다.
- 데이터 증강 기술을 이용해서 데이터 개수를 늘려주는 기술이 필요하다.

데이터 증강 기술
- 이미지 회전과 무작위 변환을 적용해 훈련 데이터의 다양성을 증가시키는 기술이다.
- 데이터의 양 및 개수를 늘려 과적합을 방지한다.
- ★ 훈련 데이터에만 적용한다!!!
- 오히려 학습에 방해되는 경우가 있으므로 적당히 데이터를 변형시켜야 한다.
- 예시로는, 크기 조절, 회전, 밝기 조절, 색깔 변경, 잘라내기, 등이 있다.
- 영상 데이터에서 이미지 데이터 개수가 100개가 있다 해보자. 이걸 10000개로 늘리는 것은 사실상 불가능에 가깝다.
그래서 기존에 있는 이미지들을 데이터 증강 기법을 통해 데이터 개수를 늘려주는 것이다.



데이터 증강 기술 필요성
- 과적합 문제
- 이미지 데이터 개수 추가

데이터 전처리 → 인스턴스화
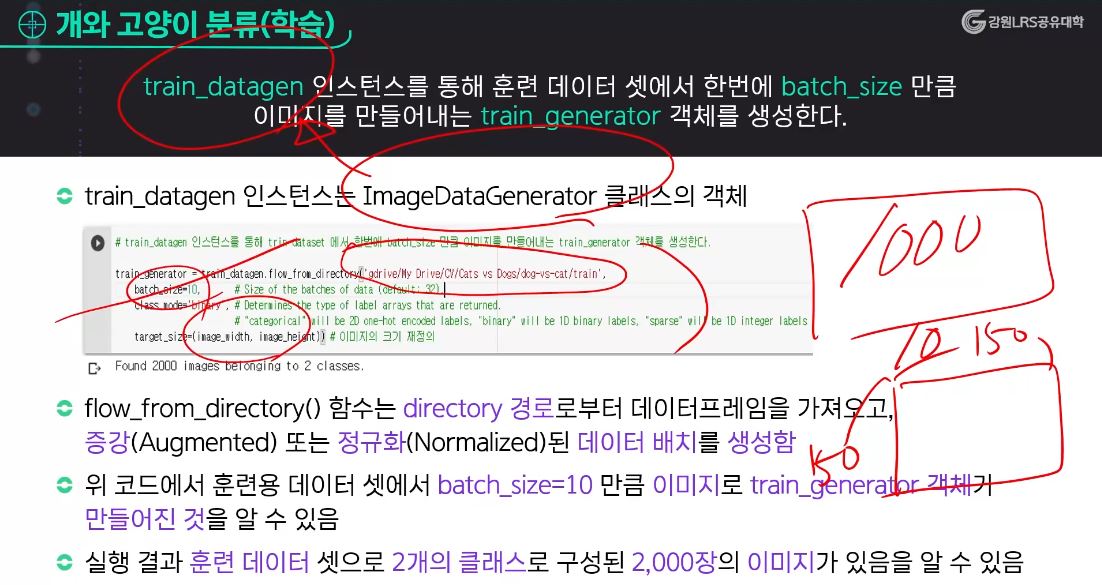
train_datagen : 인스턴스

ImageDataGenerator 클래스 과정
- ImageDataGenerator 객체를 생성하면서, 데이터 증강을 수행할 유형들을 지정한다.
- 1단계에서 생성한 ImageDataGenerator 객체를 생성한 후 훈련 데이터에서 배치 크기만큼 이미지를 만들어 낸다.
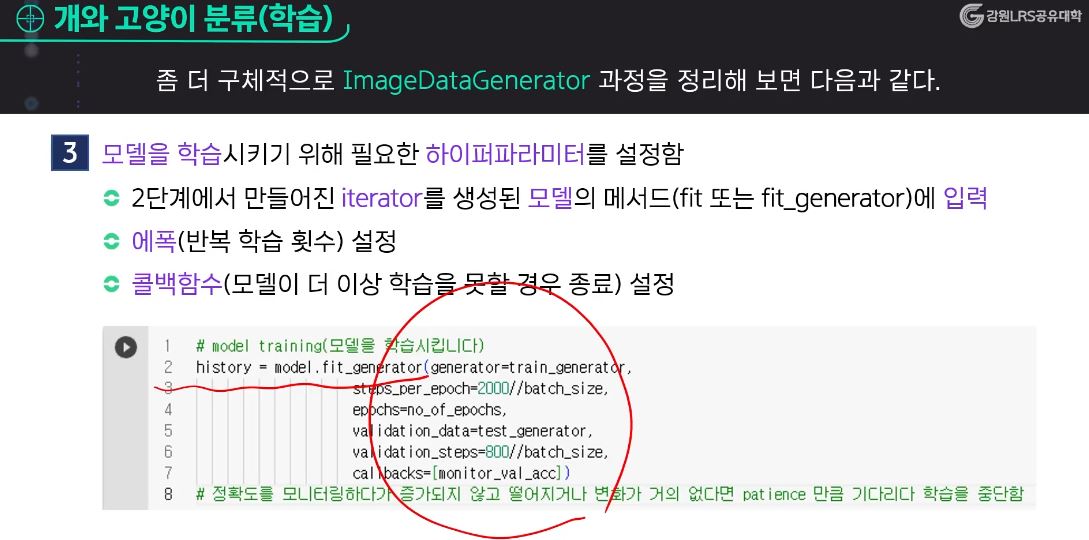
- 모델을 학습시키기 위해 필요한 하이퍼 파라미터를 설정한다.
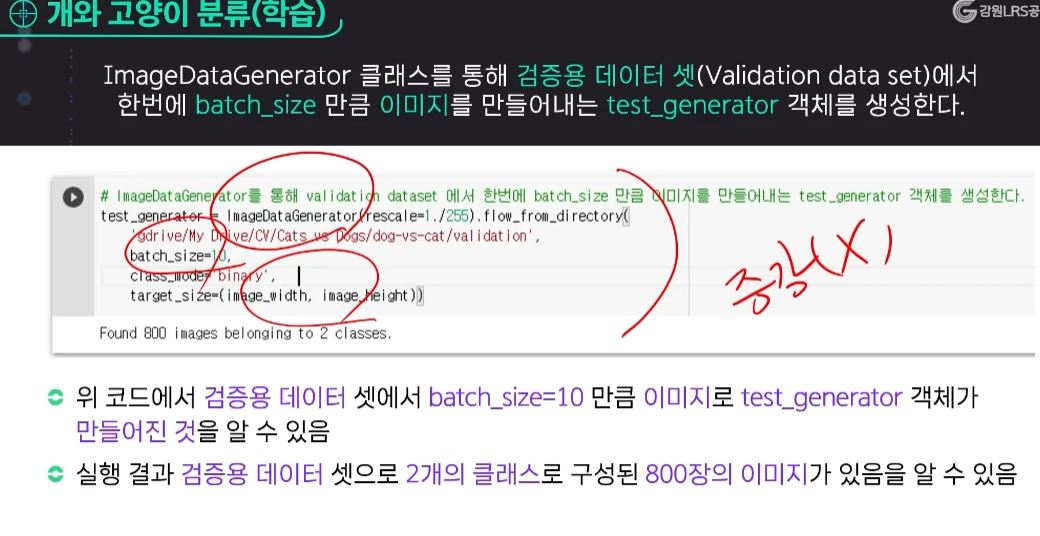

※ 테스트 데이터, 검증용 데이터에서는 데이터 증강 기술이 이루어지지 않는다!!!! test_generator : 증강X

▶ Train_generator 객체가 만들어 내는 이미지의 클래스 인덱스를 확인해보면 객체 변수의 자료구조는 딕셔너리이다.
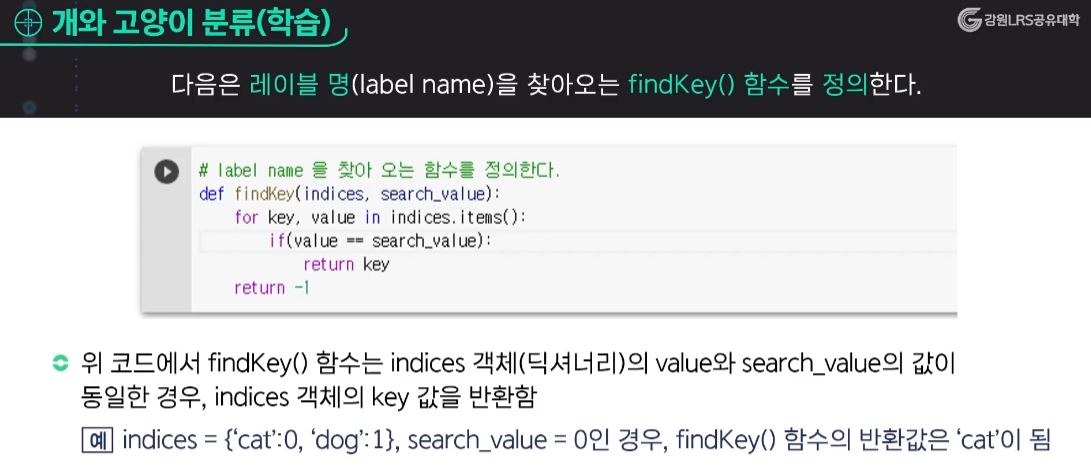


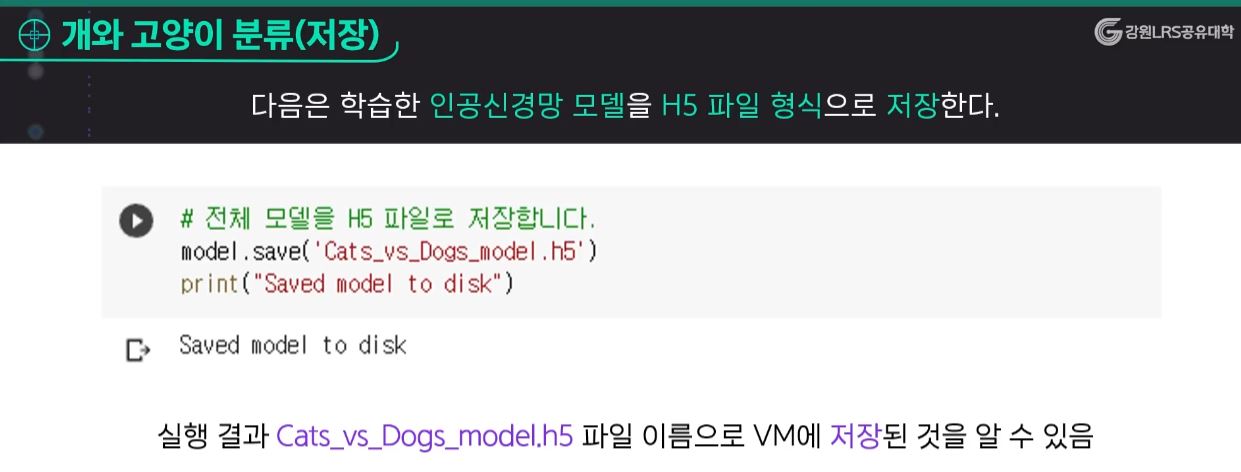
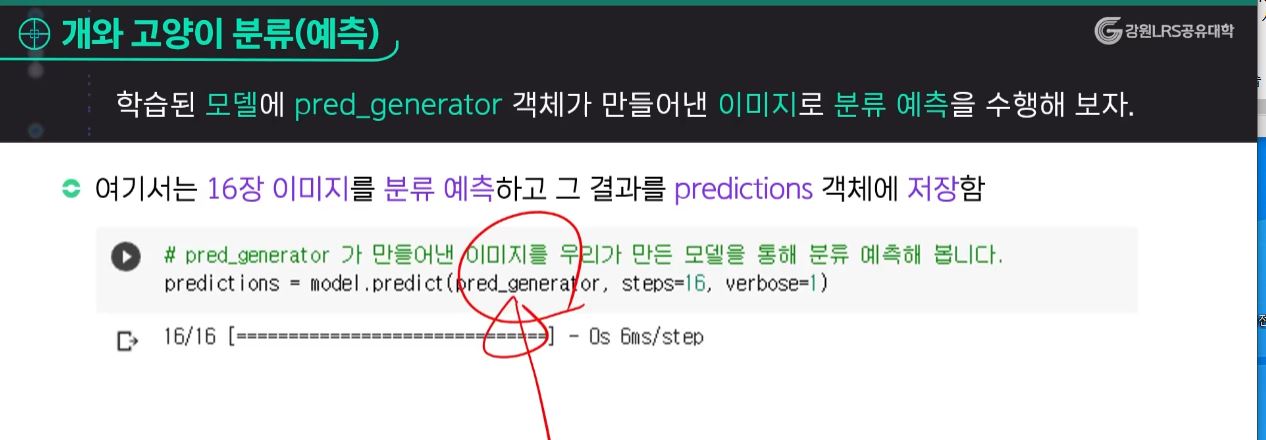
개와 고양이 분류(학습)
- 정답이 있는 데이터를 가지고 학습 → 지도학습에 해당한다.


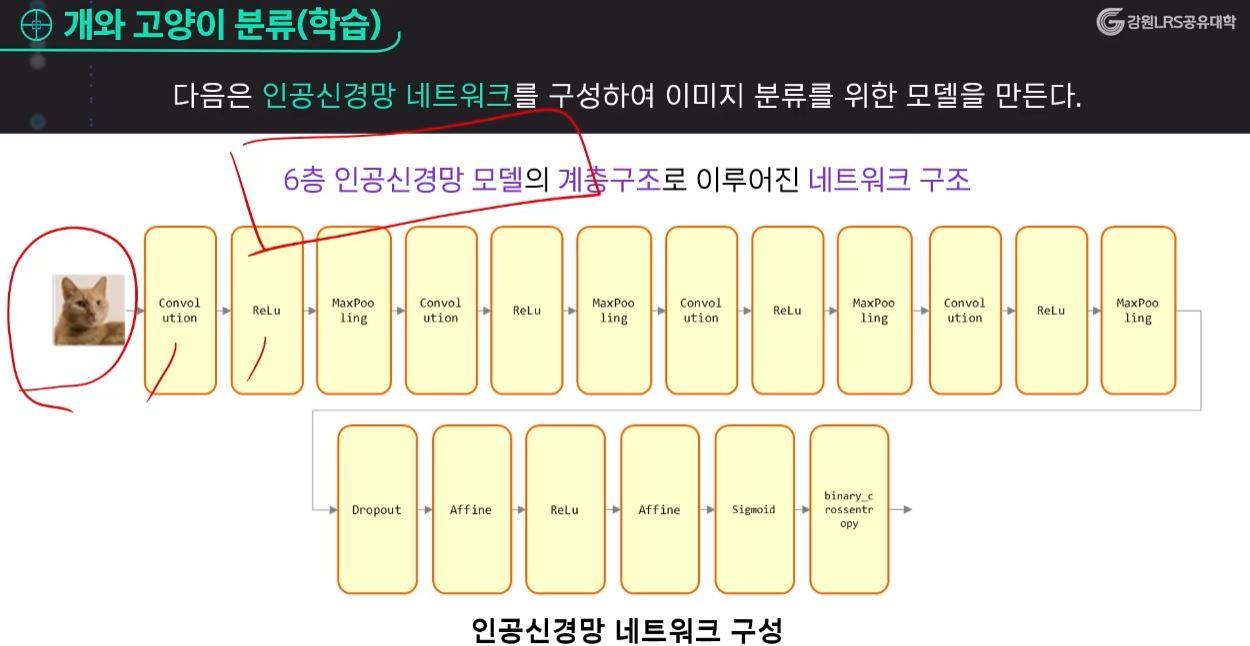
인공신경망 네트워크
- 순전파와 역전파를 통해서 우리가 구해야할 것은 각각의 중간에 들어가 있는 매개변수와 그냥의 값들을 조정해 가는 과정의 학습이라고 하는 것이다.
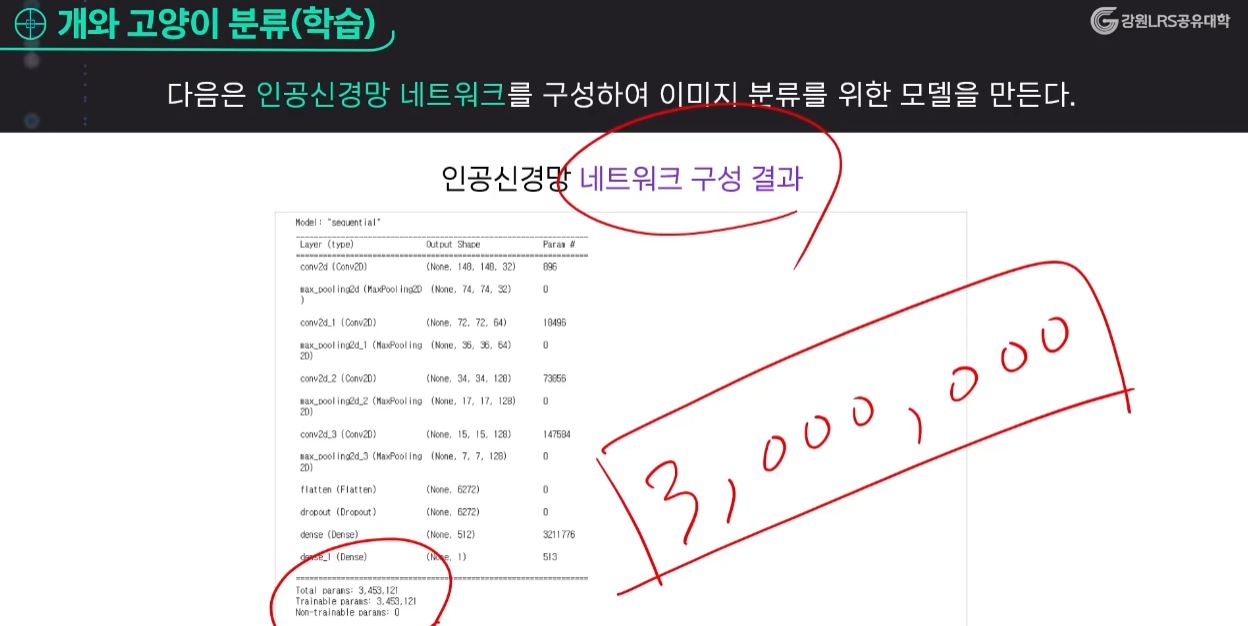
인공신경망 네트워크 구성 결과
- 340만 개 이상의 매개변수가 있다는 결과가 나왔다.
- 그만큼 딥러닝 알고리즘을 학습을 시키는 데 많은 데이터가 필요하다는 것이다.
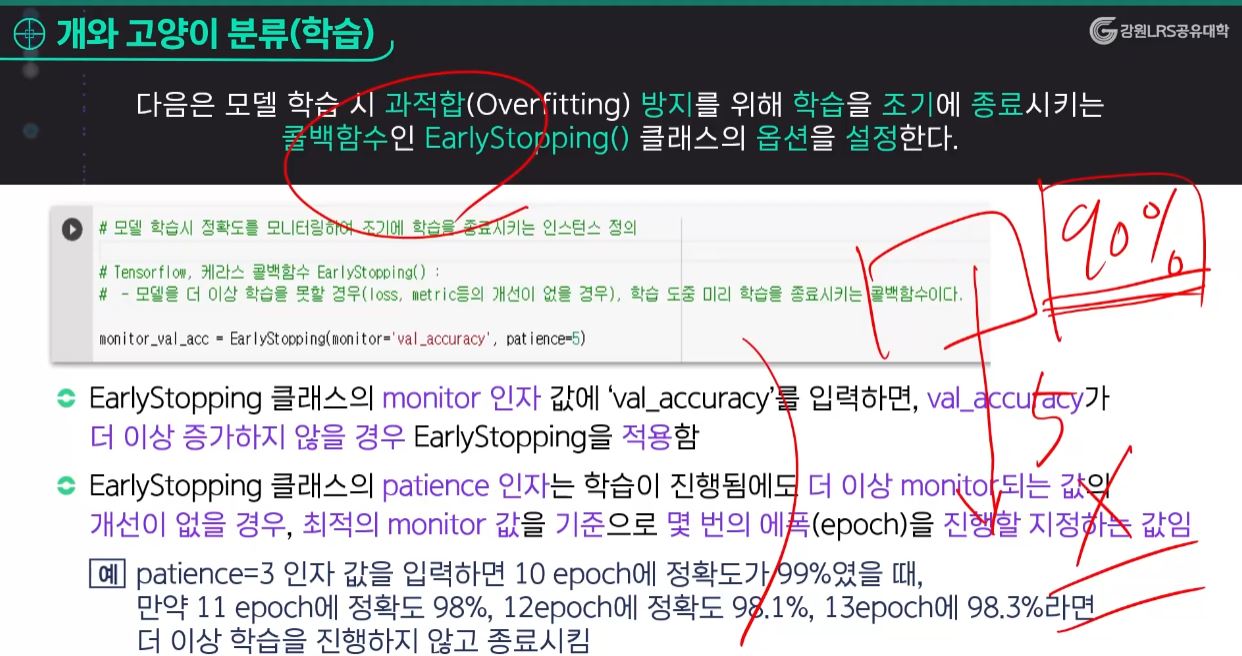
callback( ) 함수
- 모델을 더 이상 학습을 못할 경우, 학습 도중 미리 학습을 종료시키는 함수 → 학습 시간 단축





0 또는 1로 이진 분류하는 함수
- 어떤 문제를 풀 것이냐에 대해서 이진 문제를 풀 것이라고 정했기 때문에 출력층의 활성화 함수를 시그모이드 함수로 정했다.



'컴퓨터 비전 수업 > 수업 필기' 카테고리의 다른 글
| 컴퓨터 비전 6주차(1) (0) | 2024.10.27 |
|---|---|
| 컴퓨터 비전 5주차(3) (0) | 2024.10.27 |
| 컴퓨터 비전 5주차(1) (0) | 2024.10.27 |
| 컴퓨터 비전 4주차(3) (0) | 2024.10.27 |
| 컴퓨터 비전 4주차(2) (0) | 2024.10.27 |